This is an archive of past discussions. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page.
We may have discussed it before, but for example, look at Vincent Price (Q219640). As a reader I want to know how each marriage ended, was it a divorce, an annulment, or the death of the spouse, or in the last marriage the death of the subject. We struggled with various methods at the English Wikipedia with a back and forth between competing methods, followed by purges of the data, then it was back to ad hoc additions with various methods when things cooled down. --RAN (talk) 23:03, 1 November 2019 (UTC)
I think that this discussion is resolved and can be archived. If you disagree, don't hesitate to replace this template with your comment. SCIdude (talk) 15:11, 5 November 2019 (UTC)
Projectwide taxon item confusion
Lately I've been going through the tedious, yet mostly satisfying work of adding species kept (P1990) to zoos, like Edinburgh Zoo (Q1284778) for example. However, there's a problem I've noticed: there are a shocking amount of (seemingly?) redundant taxon items, often related to scientific synonyms, like Zoothera dohertyi (Q21129670) and Chestnut-backed Thrush (Q903833), which both are about the same species of bird. Often times on these items, only one receives all wikilinks, and they differ in identifiers, even on the same websites. Is it safe to merge these when I come across them, or is there something I'm not getting? --AmaryllisGardenertalk04:22, 1 November 2019 (UTC)
If I follow the specialists correctly, the items are really about taxon names. Each name has a separate history/identifiers etc. It's an oddity of these that they group sitelinks on one of the items for the same species. --- Jura06:46, 1 November 2019 (UTC)
Adapting Gravemap for WiRs (javascript skills needed)
Hi all. If someone has some javascript skills and a spare hour, would they be interested in having a go at adapting the source code of the gravemap UI to show the results of this wikidata query? The default map unfortunately has lots of items overlap in location and so hide one another. I've asked the original dev (user:Yarl) but they're swamped at the moment so I thought I'd open up the call to the community just in case. T.Shafee(evo&evo) (talk) 10:58, 1 November 2019 (UTC)
Can anyone help with "Potential Issues" when creating a new statement?
I'm hoping someone can help with "potential issues" when "creating a new statement." I am a musician and when I enter my Spotify ID, the "potential issues" icon comes up upon publishing. Does this mean A) My data won't read when searched in google? It seems everything I enter has a potential issue, and none of the potential issues are true: IE, when I enter my spotify artist ID, it says one of the issues is that I am not Human or a Musical Ensemble. Two things I know to be true. Thanks!
There is the additional complication here of polyphyletic groups of organisms known under a single common name-- e.g. algae (Q37868). That group may be a subclass of some higher-order group (for algae (Q37868), eukaryote (Q19088)), without having a parent taxon. But then you get an error because the higher-order group (itself a taxon) is not a subclass of anything. (I tried to add one at eukaryote (Q19088) before I knew the rules and got reverted[2].) Calliopejen1 (talk) 23:37, 31 October 2019 (UTC)
Others also have instance of individual animal (Q26401003), but there is still a constraint violation on the first statement. This should be changed, but I'm not sure if the best solution is to change the constraint, or create a new property. Peter James (talk) 12:47, 1 November 2019 (UTC)
There is already a ProofWiki ID property that links to articles in all namespaces of the proofwiki wiki. Is this the right approach or is better to create multiple properties, like "ProofWiki proof ID", "ProofWiki mathematician ID", "ProofWiki definition ID", etc?
The second approach would help to restrict the domain of the single properties to "proof", "mathematician", "definition", etc instead of "mathematical concept".--Lore.mazza51 (talk) 22:06, 1 November 2019 (UTC)
@SCIdude: I'm referring to the properties of the property. Having multiple properties allows to more easily recognize mistakes in their use because a property like "ProofWiki proof ID" can be used only for proofs while "ProofWiki ID" can be used for a mathematical concept, a mathematician, a book, etc.--Lore.mazza51 (talk) 15:03, 2 November 2019 (UTC)
For sites with different identifiers for different things (e.g. "123" is a work in one scheme, but a creator in another scheme), there needs to be separate properties.
If it's just the same identifier that is used for different things, we generally don't try to split the IDs (e.g. "123" is a person, "124" a work).
There was some debate if wikipages should be considered external-ids at all. The initial consensus was no (use string-datatype), now it tends to a yes (use external-id-datatype).
We currently list where people are buried in their entry, is there any interest in the reciprocal property, listing the people buried in the entry for the cemetery? It could easily be done with a bot, we could even gray-out the data so it can only be edited from the person's entry. We always assume people are going to using SPARQL to query Wikidata. I think most people will come to it from a Google search, especially for entries not in Wikipedia. --RAN (talk) 23:50, 2 November 2019 (UTC)
You can activate the gadget "relateditems" for this purpose. It displays inverse statements, e.g. on an item for a cemetery it lists people buried there. --Pasleim (talk) 03:46, 3 November 2019 (UTC)
I don't think this would be a good idea. Not everything has to be reciprocal, and this sort of approach would make the parent items very unwieldy. Andrew Gray (talk) 11:24, 3 November 2019 (UTC)
Autocompletion for properties in search box?
Is there a way to get autocompletion for properties in the search box at the top right-hand corner on this wiki?
For what can I use QuickStatements for Wikimedia Commons and where is the Syntax for that described. I want to add Captions and it where great if it works with QuickStatements or is there another Tool I can use for it. -- Hogü-456 (talk) 15:46, 3 November 2019 (UTC)
I ran across a couple of items yesterday which had "unknown" (unknown (Q24238356)) as the specified value rather than the unknown value special value. It looks like this is reasonably common for two specific properties - copyright status (P6216) and use restriction status (P7261), which have about 145k uses, and ~500 on all other properties.
The Wikidata datamodel generally allows you to be able to know whether or not two items have the same value by seeing whether they link to the same item. If I ask a question like: "What's the last book that the author who published the most books that were published at publisher X?" Wikidata should be able to answer that question to the best of it's knowledge. When we start to model all books where we don't know about the author as if they were written by the same author anonymous (Q4233718) a question like that gets answered wrong. Translating the commons template this way instead of translating is as unknown value would bring us many errors like that.
I notice the maps and graphs on Wikidata:Wikidata in Wikimedia projects#Maps_and_graphs are broken, it looks like there has been some backend changes that have broken it, it doesn't look like there have been any changes made to the page its self. Does anyone know how to fix it, I don't have the technical knowledge to fix it myself.
Best practices for documenting a person's immigration/emigration?
What is the best way to describe a person emigrating from their birth country and immigrating to a new country (i.e. more or less permanently)? The dates, source country, and target country could be modeled. Are there devoted properties, or would it be something like significant event (P793) -> immigration (Q131288), with qualifiers such as date and "from"/"to" nations? -Animalparty (talk) 22:34, 3 November 2019 (UTC)
No, just give the most specific statement(s). Any software using WD should be able to deduce USA/New York from New York City. SCIdude (talk) 07:40, 4 November 2019 (UTC)
New template for SPARQL query pages
I’ve put together a new template, {{Query page}},
which allows you to store a query on a dedicated wiki page and transclude it elsewhere in a variety of styles.
This is convenient because when you need to update the query
(e. g. due to data model changes, item merges, changes to the query service software),
you only need to do it in one place and then everything that transcludes the query will be updated automatically.
@TweetsFactsAndQueries: While this is nice, longer-term IMO it would still also be good to be able to have more of the functionality of Quarry for WDQS
(phab:T104762 "Setup sparqly service at https://sparqly.wmflabs.org/ (like Quarry)") -- a service that would remember one's queries, allow one to label them, and also to share them, so that one could more easily retrieve and revisit one's own old queries, without one having to save a url or copy a query to a wiki page for each one. The ticket could use some love, to show this is still something the community would value. As User:Legoktm implies in this comment [4], such a service, that would mint its own URLs, might well be preferable to a URL shortener that changes URL every time the query is modified, and currently refuses to shorten queries over 2000 characters. Jheald (talk) 08:15, 4 November 2019 (UTC)
@Jheald: that’s a separate need, though, isn’t it? phabricator:T104762 is about freezing a query and its results at a certain point in time, whereas {{Query page}} facilitates making both variable, so that you can update the query later when necessary.
@TweetsFactsAndQueries: The top of the ticket talks about "a web service where people can make SQL queries and share these queries and the result". It seems to me that the making and sharing (and remembering) of queries is the primary ask of the ticket, presenting an archived snapshot of a set of frozen results is an additional further ask. In that respect, I think User:GZWDer ("Bugreporter") may have been wrong to close phab:T211130 as a duplicate -- really it's an additional sub-task.
Quarry also allows one to go back and edit and re-run an existing query, so a query can be updated under the same URL when necessary.
The point of the ticket, I think, is to have a service that takes care of all of the remembering and publication of a query itself, like Quarry, without having the user having to go through the hoops of saving the URL somewhere, or copying the query to a wikipage (with or without added Listeria monitoring). Jheald (talk) 10:49, 4 November 2019 (UTC)
Upcoming: Next Linked Data for Libraries LD4 Wikidata Affinity Group call: Martin Poulter on Wikidata projects at the University of Oxford, 05, November. Agenda
SPARQL RC is showing the recent changes on items that are listed from a specific query. It is very useful to monitor the changes on a specific subset of data, for example data that you recently imported in Wikidata.
Made the Lua functions mw.wikibase.getBestStatements and mw.wikibase.getAllStatements faster if called more than once for the same statement on a single page
Simon Cobb, Nav Evans and myself have written Wikidata:Map_data, instructions on uploading map data to Commons and using it on Wikidata and other Wikimedia projects, its a little fiddly to say the least. Let us know if anything is missing or unclear.
Google Code-In will soon take place again! Mentor tasks to help new contributors!
Hi everybody! Google Code-in (GCI) will soon take place again - a seven week long contest for 13-17 year old students to contribute to free software projects. Tasks should take an experienced contributor about two or three hours and can be of the categories Code, Documentation/Training, Outreach/Research, Quality Assurance, and User Interface/Design. Do you have any Lua, template, gadget/script or similar task that would benefit your wiki? Or maybe some of your tools need better documentation? If so, and you can imagine enjoying mentoring such a task to help a new contributor, please check out mw:Google Code-in/2019 and become a mentor. If you have any questions, feel free to ask at our talk page. Many thanks in advance! --Martin Urbanec07:28, 5 November 2019 (UTC)
I’ve done an image search and the photo of this person is being used online dating site. Thought somebody should be made aware of this. Not sure how this site works . ? – The preceding unsigned comment was added by1.128.109.3 (talk • contribs) at 08:57, 11 November 2019 (UTC).
In recent weeks I've been improving units in Wikidata, which is still a large, ongoing and probably never ending project. Very helpful was alignment with the WL by the property Wolfram Language unit code (P7007), which allows for instance comparison of conversion factors.
Now that we have Wolfram Language quantity ID (P7431), similar, large scale improvements will be possible. However, one issue in Wikidata is the classification of (physical) quantities: What are the individuals and what are the classes? I estimate that Wikidata has items for about 1000 physical quantities, but currently there is no single query that finds all of them, and nothing more.
Proposal (using examples; for precise terminology, refer to the text):
5 kg, 3 apples, 5 rad, ... are individual quantities
length, area, radius, apple count, ... are classes of individual quantities
radius is a "subclass of" length; lengths is a "subclass of" physical quantity
5 kg is an "instance of" mass; 5 kg is also an "instance of" a physical quantity
Notes on Defining 'kind of quantity' (Q71548419): Page 5, figure 2 illustrates this idea very nicely. The box called M0 are what Wikidata calls "instances". The box called M1 contains classes, solid arrows are "subclass of" relations in Wikidata.
If we consistently follow that scheme then query [1] will contain exactly those elements that we have in mind when talking about "physical quantity".
I'm writing this comment to raise awareness of the tricky issue "instance of" vs "subclass of" in the context of quantities, to solicit feedback, support or criticism, and potentially pointers to previous discussion that I have missed.
[1] Query physical quantities (the classes like "length", "area", not the individuals like 5 m, ...):
@Toni 001: Thanks - this is clear enough, and I Support your approach. This use of instance of (P31) when it more logically should be subclass of (P279) is a very general problem within wikidata's class hierarchy, and we've been rationalizing it a bit with arguments about metaclasses, but I think just converting more of those abstract relations to subclass relations would work in most cases (and I agree it makes sense in this one). ArthurPSmith (talk) 17:17, 21 October 2019 (UTC)
Comment$ I think the general question is which ones are instances of units and which ones are classes of units. Anything with a SI conversion should be an instance. --- Jura13:55, 23 October 2019 (UTC)
@Jura1: This suggestion is about quantities, not units. The relation is that a quantity (that is, an instance of physical quantity) is a composite object, the two components are: number and unit. Toni 001 (talk) 15:38, 23 October 2019 (UTC)
There are currently about 1700 subclasses of physical quantity (Q107715). This is already pretty good (compared to a week ago): I guess less than half of them don't belong there, and some (not sure yet, could be hundreds) are missing.
There are currently about 11000 instances of physical quantity (Q107715) (or subclasses thereof). This list is what should contain things like 5m, 45°, but contains a lot of things that should not be there. This will be a bigger project to clean that up, and might trigger some separate discussions. For instance, the list contains the year 1184. Is that really an individual quantity? This item states "instance of year", and year states "subclass of orbital period". Both statements don't seem wrong when looked at individually, but the issue is that "year" has two different meanings: A point (well, somewhat spread) on some time scale / calendar, and a duration. The latter is sometimes called "annum" to distinguish it from the former.
To summarize, I first want to concentrate on point 1, getting quantity classes cleaned up, and in the process tighten some property constraints (for instance, measured physical quantity (P111) currently allows both subclasses and instances of physical quantity as values - it should only allows subclasses).
Toni 001 (talk) 19:34, 23 October 2019 (UTC)
Well, top-down queries tend to get surprising results if they don't time out. It's generally easier to fix things bottom-up. --- Jura08:54, 24 October 2019 (UTC)
@Jura1: Yes. The top-town approach is important for understanding the ontology. Here is an example of a query that will help improving quantities bottom-up: All the quantities described by ISO/IEC 80000 (Q568496); I guess that list contains less than 10% so far, so I'm going through the standard to add values for described by source (P1343):
select?quantity?quantityLabel?quantitySymbols?wlQuantity?source?sourceLabel?itemNumberwhere{?quantitywdt:P279+wd:Q71550118.# quantity?quantityp:P1343[ps:P1343?source;pq:P958?itemNumber;].?sourcewdt:P629/wdt:P361wd:Q568496.# any edition of any part of ISO 80000optional{?quantitywdt:P7431?wlQuantity.}servicewikibase:label{bd:serviceParamwikibase:language"en".}optional{select?quantity(group_concat(?quantitySymbol;separator=", ")as?quantitySymbols)where{?quantitywdt:P416?quantitySymbol.}group by?quantity}}order by?itemNumber
Oppose There's some leak in this scheme, and I can imagine where. Compare density (Q29539) and intensive quantity (Q3387041). In your scheme they are both subclasses of physical quantity (Q107715) which is illogical. From my point of view physical quantity (Q107715) should be M2 (metaclass), intensive quantity (Q3387041) and similar would be its subclasses (and thus also M2), and items like density (Q29539) (which has definite units of measure) are P31 of any previous (and thus M1). I don't care about M0 (which you call "individual quantities" but I'd rather call them "individual measurements") now as they seem to be rare in WD, but I suspect that there should be another relation (not P31) between them and M1-quantities. --Infovarius (talk) 22:58, 27 October 2019 (UTC)
Number-unit-combinations like 7 g/m^3 are called individual or particular quantity in different standards. There is a class for all of them, individual quantity (Q71550118). This class contains various subclasses, formed by applying objective or conventional restrictions, which are described by adjectives or qualifiers like "physical", "chemical", "intensive", "extensive", "areal", "molar", "base", "computational", ... . Those classes can overlap, as their restrictions are concerned with different aspects of quantities. Those classes then contain further subclasses which refer to a particular "property of a phenomenon, body, or substance" (definition of "quantity" in VIM3), for instance density, length, radius, wavelength and so on. That is a "flat", but consistent model, far from illogical.
It is, at least at de:wp, totally normal that a reference has a retrieval date. And I don't see a reason why this should not be applied here also. Steak (talk) 15:16, 5 November 2019 (UTC)
If something is normal, then it doesn't need to go in a constraint for a specific property. If you want to add a constraint to Elo rating (P1087), you have to make a case for why it matters for the specific property in a way it doesn't matter for other properties.
Wikidata works on the assumption that if a data user like dewiki which only wants to have data with retrieval dates, dewiki model can do the appropriate filtering and can load only data it wants. ChristianKl ❪✉❫ 15:29, 5 November 2019 (UTC)
If someone wants to go through all statements of a property to ensure they are properly sourced, I don't see much of an issue to add such a constraint, preferably probably as a suggestion constraint.
The main problem with P1087 I realized only later seems to be that there is only one reference for it anyways (actually apparently there is another for earlier years). --- Jura09:19, 6 November 2019 (UTC)
I am working (with the help of members of a small non-wmf wikicommunity) on openaccess wikiarticles about various drugs. We are planning on incorporating information about various medical substances that are available through wikidata in the future. Through our project we already donated numerous photos of different drugs/drug forms to commons.
For our users - medical students, nurses and doctors alike - are information about the physical attributes of the drugs very useful and we would like to add them to wikidata and afterward to our project. But I am not sure how to add this kind of information to wikidata, there are two barriers I would need advice with:
the physical appearance of the drug form, such as "white, round tablets" are specific per manufacturer and the drug, is it viable to set up new wikidata items for the drug by specific manufacturers /say "Metformin Teva 500mg" - an item for tablet containing 500mg of metformin produced by Teva company/?
are there any properties on wikidata already in place that could be used for the physical appearance description?
1. We already have items on compound level (like sildenafil (Q191521)) and product level (like Viagra (Q29006643)). You are proposing even one more deeper specific product level. As long as these items will be properly sourced and connected with "product level" it seems acceptable to me.--Jklamo (talk) 19:40, 4 November 2019 (UTC)
Does it suffice to stay on the product level and put multiple pictures there, distinguishing them by a qualifier value? --SCIdude (talk) 05:01, 5 November 2019 (UTC)
Thank you for your response Jklamo. I will discuss with the team if we actually need the deeper level, because as SCIdude suggests (if I understand it correctly), the different dosages of similar products (say Metformin Teva 500mg and Metformin Teva 850mg) might not need independent items, but be distinguished by a qualifier within an item for Metformin produced by Teva. --Wesalius (talk) 18:40, 5 November 2019 (UTC)
I think it's desireable to have Wikidata items for specific packaging like "Metformin Teva 500mg" when the new items are correctly linked to the existing items. The main reason that we currently don't have those items is that it's a decent chunk of work to create them.
I would prefer to have separate items for compound/product/packaging whereby the packaging subclasses the product. Independent items have the advantage that it's possible to be more specific. This would allow us to store information such as Global Trade Item Number (P3962) in Wikidata for the different packaging. That would allow it for someone to program an App that simply scans the barcode of a drug and then goes to the correct Wikidata item. ChristianKl ❪✉❫ 10:01, 7 November 2019 (UTC)
a thought for longer-term: works, editions, and searching
This is just a thought for consideration... Literary works are supposed to have one item for the work in general and an item for every edition. Now, if there are items for every edition, searching and auto-completion become quite unwieldy, you have a long list and it can be hard to figure out which is the item for the work. Most of the time it's the work you'll be looking for. This only affects a few works so far, but it'll be a big nuisance if the literary part of the data keeps growing. Has anyone yet given a thought to solutions? Not necessarily to be implemented now, but to be mulled over. Like, here's something I imagine, I don't know if it'd be workable: suppose in the list that comes up for searching and auto-completion, items that are instances of "literary work" or subtypes ("Poem," etc.) would come up just as usual, but there would be a single differently-colored entry for "edition, translation, or version;" and this item would not be an ordinary entry, but instead, clicking on it would take you to a sub-list of all editions (but if there's only one, it would automatically select that). Levana Taylor (talk) 02:50, 5 November 2019 (UTC)
It would be nice if searches allowed the user to restrict searches to works or editions. Libraries do this with their databases: having records clearly marked as "Author/Person" or "Work" or "Edition/Copy in the Library (Bibliographic)". I'm not sure how we could do that here, since the Wikidata collection of items includes many thousands of additional items that aren't books or editions or authors. --EncycloPetey (talk) 16:49, 5 November 2019 (UTC)
There is a way to do something like this but it's not very convenient in the UI - basically you have to add "haswbstatement:P31=Qxxxxx" in the search box, where Qxxxxx is the id of the class you want to restrict the search to. For example to find only items which are instances of "book" try something like "Paleontology haswbstatement:P31=Q571" in the search box. ArthurPSmith (talk) 19:39, 5 November 2019 (UTC)
@ArthurPSmith: There is a way to do something like this but it's not very convenient in the UI Unfortunately, that seems to be a common theme with Wikidata. --Trade (talk) 19:48, 5 November 2019 (UTC)
How is that unfortunate? It simply means that there are a lot of ways programming resources can be used to improve Wikidata and a lot of ways to grow. ChristianKl ❪✉❫ 16:40, 6 November 2019 (UTC)
Apparently, there isn't much, if any, interest in working with these pages.
It seems that we mostly loose potentially interested contributors who try to create a subpage there, get a mostly pre-filled page and that then ends up being abandoned.
I agree that this space is not really working as it should at the moment. I think these pages could potentially be improved instead of deleted, by trimming down the content of the template that generates them. See my comment at Wikidata_talk:Dataset_Imports#Feedback_on_the_import_pages. But if no one wants to take care of that, we should not incentivize newcomers to use this space, since their efforts will likely go unnoticed. − Pintoch (talk) 18:54, 6 November 2019 (UTC)
Thanks for your feedback. I noticed your comment when cross-referencing this there. Seems we made similar observations. Earlier versions were actually much more readable (there was just one page), but even that didn't draw much attention. --- Jura13:56, 7 November 2019 (UTC)
"Ramses" (Q1343144)
Hi, the above data item was extensively edited by an IP address, and removed a lot of stuff, added some other things. Other editors tried to fix it (like me) as the current description (South African hip hop artist) is not "Ramses Shaffy", Dutch singer. Can someone reset the whole thing to whatever it was before IP started editing (and I assume all was well)? I looked in the history, but am not BOLD enough to click the button. Thank you. Deadstar (talk) 09:24, 7 November 2019 (UTC)
National Gallery of Art (Q214867) as an art museum is both an organization and a building, so should it have a headquarters or be located in an administrative territory? They are mutually exclusive, and naming the architect requires that it be a building that is "located in [an] administrative territorial entity". --RAN (talk) 13:47, 6 November 2019 (UTC)
I'd prefer to challenge the 'mutually exclusive' constraint. If we consider a museum organisation (say, York City Museum) operating from a museum building (York City Museum Building), there is no logical reason why we should be able to say that the building is P131=City of York but not say that the organisation is P131=City of York. To that end, I'm agitating right now on P131 talk. Where we have so many organisations (especially schools, libraries, museums) where the org and the building are effectively represented in a single item, the constraint that orgs should have no P131 values causes harm for no obvious gain. --Tagishsimon (talk) 21:30, 6 November 2019 (UTC)
I agree that they can be combined into one entry, unless they have multiple buildings or have moved from one building to another. For instance a church can be a building and a congregation that have different inception dates. But if they are the same, keep one entry. --RAN (talk) 15:35, 7 November 2019 (UTC)
Tagishsimon explained it well. Some people have a very narrow world view and are trying to enforce that by adding constraints. I removed this one. Multichill (talk) 20:34, 7 November 2019 (UTC)
Lexeme mistakes
The following Lexemes are about German nouns, which are capitalized without exception:
Yes, the first thing to do, would be to find duplicates and merge them. I couldn't find a tool where you can type in Lexeme names and get a L-number. The second thing would be to change Lexeme names automaticly with a tool, a guess this could work with QuickStatements Greetings Bigbossfarin (talk) 18:59, 4 November 2019 (UTC)
Indeed, I can delete them and send them back to the curators for checking if they find more errors. Would that be OK? Wpbloyd (talk) 10:13, 6 November 2019 (UTC)
@Wpbloyd: Where do the items come from? If you mean "upload to Wikidata" with "send them back to the curators for checking" that feels a bit dubious to me. ChristianKl ❪✉❫ 13:33, 6 November 2019 (UTC)
@ChristianKl: the terms comes from an Internal curated list of an architectural archive, so I meant to send the list back to the curators for checking that everything is fine Wpbloyd (talk) 13:49, 6 November 2019 (UTC)
@Wpbloyd: For future uploads, would you check here on project chat or with the relevant WikiProject before uploading? We already had problem with your other upload and if you upload data you don't any basic checks, it deteriorates overall data quality. --- Jura13:22, 8 November 2019 (UTC)
What was the library used for visualizing the result of wikidata sparql result?
I am wondering if you can point me out to what is the library used to visualize the query result of wikidata query. I am actually impressed on how the timeline was implemented. I would like to create a similar GUI for my project. – The preceding unsigned comment was added by126.140.210.87 (talk • contribs) at 11:56, November 7, 2019 (UTC).
Is sport-hunting or big-game-hunting actually a sport? Or is it just an activity? It isn't a competitive sport like tennis, but is it a sport by Wikidata's definition? --RAN (talk) 13:11, 7 November 2019 (UTC)
There's no (by Wikidata's definition) in most cases. Wikidata generally tries to match what can by shown with sources. ChristianKl ❪✉❫ 17:38, 7 November 2019 (UTC)
In Wikidata, "sports" are defined with a subclass tree under sport (Q349), and that item itself is a subclass of physical activity (Q747883). Thus, different types of sport are sort of more specialized versions of physical activity. I personally do not like this approach for several reasons, but this is what has evolved over time and some properties are relying on this subclass hierarchy.
Currently, a lot of info of each WikiJournal article is stored in the v:template:article_info (essentially in infoboxes). It'd be ideal to be able to easily synchronise this over to wikidata (list of submitted articles ; list of published articles). We used to import metadata for published articles from crossref to wikidata via sourcemd, but that not working currently, and also crossref lacks a lot of useful metadata. Would it be possible to synchronise this so that it's imported into wikidata, then transcluded back over to the wikijournal page? This should also help to automate the tracking table that currently has to be updated manually. It'd similarly be useful to add editors from this page to wikidata (either to the journal item or to the item for the person as appropriate). T.Shafee(evo&evo) (talk) 09:31, 9 November 2019 (UTC) edited T.Shafee(evo&evo) (talk)
Completeness of Lists
How can we indicate that a set of relationships is complete? For instance, AK-74 (Q156229) has the conflict (P607) property. This list doesn't include every conflict that this entity is related to.
The use case for this is to make exclusionary queries like "In which wars in the 21st century was the AK-74 (Q156229)? not used." possible.
If a list can be marked either as "exhaustive" or "not a complete list", it would help deliver clear answers or inform the asker of any ambiguities that may exist.
I think adding a new unknown statement would indicate that there is more to the property that is not known... but I'm curious what others think. U+1F360 (talk) 17:22, 4 November 2019 (UTC)
@Jura1: Good question. Maybe not for this specific property, but for some other types yes. That's yet another reason to indicate completeness (or lack thereof) of a set: To know if a "negative" question can be answered at all. – The preceding unsigned comment was added byWeslima (talk • contribs).
The lists has 337 entries, the property 45,237 uses. Even if not all uses are for TV series, what does it duplicate? --- Jura20:40, 4 November 2019 (UTC)
@Jura1: I think we may be talking about two different things. I believe expected completeness (P2429) implies the completeness of the entire property (all usages of it) rather than some usages of it. For instance, what if in one instance, the list is complete, but in another instance, it is not? U+1F360 (talk) 14:20, 5 November 2019 (UTC)
@U+1F360: one could qualify P2429 statements for different P31/P279. Maybe for ABC it could eventually be complete, for others it can't really.--- Jura19:52, 5 November 2019 (UTC)
I think that rather illustrates that it's sufficient to do that on a per property basis for this property. --- Jura18:11, 6 November 2019 (UTC)
@Jura1: I don't understand. Let's say you have three uses of conflict (P607), one is complete, another is incomplete and can be completed, and another is incomplete and cannot be completed. Should we make three different properties and move the values between them when the use moves from one to another? U+1F360 (talk) 18:15, 6 November 2019 (UTC)
Well that's an important point, should it always be assumed to be incomplete (even if that is known to be untrue)? U+1F360 (talk) 18:21, 6 November 2019 (UTC)
@U+1F360: well, I was actually looking for a sample with conflict (P607) discussed earlier.
Still has part(s) (P527) is somewhat comparable. How do you know it's complete? Ideally you would have a reference stating that there are 8 themed areas. Oddly, the references omits one mentioned in Wikipedia that has also an item (Q16932605), but isn't linked and somehow you created a duplicate for Q2623650. Still, let's agree we actually have all themed areas and can reference that. The nice thing about has part(s) (P527) is that it comes with a companion property has part(s) of the class (P2670) which could hold such a statement. A query could than compare them, just like number of episodes. Still, if you compare with https://petscan.wmflabs.org/?psid=13384686 , you might want to create an item for the entrance that could also be at P527. So a "part of" listing, is rarely ever complete either. --- Jura22:03, 6 November 2019 (UTC)
@Jura1: The list of themed areas is avilable in the source that describes all of them. While the source does not provide a count of how many there are, there is a defined set. Even if "entrance" and "exit" were part of it, it's not a themed area. My point is that this could happen with any property really, and there isn't a good way to express it other than the two work-arounds I provided in phab:T237472. If that's what we want to do, then that's fine, but it kind of seems like a pain when, ideally, the software should support making statements about the group of values. U+1F360 (talk) 22:12, 6 November 2019 (UTC)
@Jura1: I understand completely. I'm saying that if any statements were allowed on the group it could be qualified that way (i.e. "complete" with a qualifier of "themed areas", etc.). U+1F360 (talk) 22:28, 6 November 2019 (UTC)
@Jura1: I'm not sure what's the point of arguing away individual cases. When our properties have a clear meaning, whenever it is sensible to create statements about entity-property-pairs, it is also sensible to express the non-existence of statements other than those mentioned (that's namely what completeness says). I don't think doubling the number of properties with murky count equivalents (like child (P40)/number of children (P1971), season (P4908)/number of seasons (P2437)), which lack a formal relationship, is a good way to go. Ls1g (talk) 08:53, 7 November 2019 (UTC)
The problem is that if we generate a claim about a group that can never receive a proper reference because it can't really be referenced we just full the mistaken assumption that the results are comprehensive now and forever. For P1971, you might want to read why it was created. --- Jura12:14, 7 November 2019 (UTC)
Why should completeness be assumed to be static? For many regular statements, temporal qualifications are essential, I don't see why completeness should be interpreted differently (e.g., without temporal qualification, Bush would be still US president - completeness would only be static if the subject itself is static, e.g., band members of The Beatles).
Regarding subject-specificity and references below a few examples:
In my view the data model is really somewhat murky. We can express the odd cases of count "0" and count ">=1" or "+1" (?) as novalue/unknown on all properties, but beyond that resort to a completely different encoding via dedicated duplicated properties, one different for each base property, and without apparent relationship to their base version. Having instead generic count/completeness/incompleteness meta-qualifiers on regular properties would be much cleaner. Ls1g (talk) 14:42, 7 November 2019 (UTC)
For the above samples, I think completeness is assessed differently from one property to another. Even if one would add a group statement at a similar place, the criteria (and other statements to consider) can be different. eg. P50 is generally complete, at least if one takes in account "author name string". Is Q1299#P527 necessarily limited to band members? Will it still be complete after a year? What if a user replaces an item/adds an item/deletes an item?
Anyway, I think the question about completeness is frequently also if all instances of a given class are present. --- Jura08:06, 8 November 2019 (UTC)
"completeness is assessed differently from one property to another" -> Makes sense as each property has a different meaning?
"P50 is generally complete, at least if one takes in account "author name string"" -> That's the point, only in few cases author (P50) is complete, in others recourse to author name string (P2093), with information loss (no disambiguated entities), is needed. Besides, we have over 9000 cases where we already now explicitly state incompleteness via novalues: [5]
"Is Q1299#P527 necessarily limited to band members?" -> Good question, maybe Wikidata:WikiProject_Music has thoughts what the semantics of the property are?
"Will it still be complete after a year?" -> Same as for regular statements, is Bush still US president? Temporal qualification is needed.
"What if a user replaces an item/adds an item/deletes an item?" -> Same problem as changing statement values, should qualifiers and references stay? That's why I'm arguing for a consistent solution that collocates statements and metadata, instead of murky novalues, unknown values, and semantically unrelated count-versions of properties.
"Anyway, I think the question about completeness is frequently also if all instances of a given class are present." -> Good point, unfortunately in Wikidata's entity-centric data model that seems even tougher, as it's a statement about an inverse property (P31) for the respective class. Ls1g (talk) 10:21, 8 November 2019 (UTC)
about: "Makes sense as each property has a different meaning?": if that needs to be done anyways, one could just as well define the criteria on the property itself.
P50/P2093/author unknown: personally, I think when any of these are present, completeness is (generally) there. I don't see an advantage of marking this in addition with some completeness marker. The author was found to be unkown: we note this on the item: that statement is complete. --- Jura13:18, 8 November 2019 (UTC)
I think you dramatically underestimate the diversity of Wikidata, see the other examples above. An instance agnostic string like "participant (P710) is complete for all British rock concerts with >50k visitors since 1970 (except punk-rock), all diplomatic summits that were UN-licensed, except on cultural politics or in South America, and all naval expeditions, including submarine attacks, if they have at least three participants, except for solo-world-circumnavigations" will never even remotely match the reality of 100k subjects, nor can anyone keep it up-to-date with an ever-evolving KB, nor does it stand up to Wikidata's vision of machine-readable knowledge. Ls1g (talk) 10:33, 9 November 2019 (UTC)
Does COOL-WD cater to your purpose? Afaik, so far there is no way to express this kind of knowledge inside the Wikidata data model: The kind of statement you refer to is a statement about a pair of entity and property, so in Wikidata's entity-centric rendering, we would need to show it on properties itself, not as an additional value. Adding "unknown value" only allows to represent one side of the coin - incompleteness, but not completeness (and there is a third case, that it is unknown which of the two applies). Also as U+1F360 observed expected completeness (P2429) doesn't solve the problem, as it refers only to a property, but not to specific entities (conflicts may be complete for one subject, but not for another). Ls1g (talk) 15:47, 5 November 2019 (UTC)
Comment On all these completeness issues, do we have wikipages entry points ? I remembered to have written a couple of queries to assess the completeness of Wikidata wrt. the instances of certains classes, if we know the number of instances that exists, I know there is some tools like cool-wd. But I don’t think we have a WD:Completeness or wikiproject or help page that documents all what is done of the completeness notions/tools on Wikidata. Should we ? author TomT0m / talk page18:51, 5 November 2019 (UTC)
Comment I created phab:T237472 that I think covers the problem, a proposed solution, and the work-arounds discussed. Hopefully a more comprehensive solution can be created. U+1F360 (talk) 22:14, 5 November 2019 (UTC)
Wikidata recently introduced ShEx and it might be desireable to have a tool that tells you for a given ShEx document how complete the corresponding data happens to be. ChristianKl ❪✉❫ 09:05, 7 November 2019 (UTC)
Although ShEx can count its purpose is to prescribe schemata for classes, not for instances, so it does not help with the problem described above. Ls1g (talk) 15:43, 7 November 2019 (UTC)
Thinking more about the issue, it seems to me like the core issue for the described problem is that it's currently impossible to enter negative statements. If we would have a way to enter negative statements it would be possible to use a tool like the completness tools above. You could also use such a tool to analyse whether what's described in a given ShEx is complete. ChristianKl ❪✉❫ 10:53, 8 November 2019 (UTC)
Do we limit how many images to hold in the image field?
Do we limit how many images to hold in the image field? How many is too many? Was it designed to hold a single authoritative image, or to hold many. Are we worried about visual clutter? --RAN (talk) 16:30, 6 November 2019 (UTC)
Would that count as "in use" by a Wikimedia Foundation project, or is it still potentially out of scope and eligible for deletion at Wikimedia Commons? RAN (talk) 17:44, 6 November 2019 (UTC)
I see "not in scope, not in use" in deletion arguments. Not in scope according to Commons:Scope, translates into "not educational" which is purely subjective. The only objective criterion in Commons:Scope to avoid deletion is "in use". I am just thinking about long term archiving ever since Flickr began deleting images stored there when they dropped their 1TB of free storage. I was worried when Yahoo bought them, they have a history of dropping projects. Flickr was recently sold and if you did not pay the yearly subscription, you had to press a button allowing them to delete all but your most recent 2,000 images, if you wanted to view your account. I just noticed today that I can login without paying, and my photos are still there, but now I wonder about long term archiving. --RAN (talk) 18:23, 6 November 2019 (UTC)
@Richard Arthur Norton (1958- ): I would argue that, just because it's in use on Wikidata, doesn't qualify it as "in use" or "educational." I feel like this is a problem that commons should addresses. Though, I would also argue, as far as Wikidata is concerned, is there really a need to have more than one quality photo of every item? Most of our items don't have a image (P18). So for this project, I would say it would be better to have a breadth of images (lots of items with a single image), than a depth (lots of items with multiple images). I'm curious what the members of commons would think, but I imagine it would be a similar assessment. U+1F360 (talk) 19:01, 6 November 2019 (UTC)
@Richard Arthur Norton (1958- ): I'm not sure what Flickr has to do with the case (and as far as I know, no publicly-visible free-licensed images were deleted there). Most deletions on Commons are because of copyright issues, in which case being "in use" is no defense. Commons' notion of "educational" is pretty broad: overwhelmingly, when images are deleted for being out of scope, it's things like the umpteenth poorly composed photo of male genitalia (we have plenty, thank you) or someone's large collection of personal photos of themselves and their friends. As a rule, even things like wildly inaccurate maps or fictional flags tend to be marked as fictional or untrustworthy, rather than deleted. Do you have any examples of exceptions to that (things that were deleted on Commons as out of scope that would have been of relevance in Wikidata terms)? - Jmabel (talk) 21:05, 6 November 2019 (UTC)
I took pictures of the four tombstones of all the family members at a grave for a person with a Wikipedia article. All were nominated for deletion and deleted. The one for the person with the article was deleted but I was allowed to restore it. I recently had them all restored, only because I noticed them missing when creating entries for them at Wikidata. I am just worried that anyone can rationalize any picture not being used as "out of scope" since it is so subjective. "In use" is objective. --RAN (talk) 21:14, 6 November 2019 (UTC)
In general it's best just to have a single image (P18), which then shows up in queries/infoboxes/etc. Having more makes things a bit too random (which one gets picked?), and can cause problems with reuse, for example if some images have captions and others don't. Thanks. Mike Peel (talk) 18:49, 6 November 2019 (UTC)
The infobox displays the first image only, if you have multiple, and you do not want the first one displayed, you set the one you want displayed with "preferred rank" and that one is displayed. --RAN (talk) 19:50, 6 November 2019 (UTC)
In general I would stick to one, though sometimes it might be useful to have two or three with qualifiers (eg if we have a person with a picture from 2019 and a picture from 1979, which look very different). In this case, though, one should definitely be marked as preferred. Having four or five is probably a bad idea - create a Commons category and link it instead. Andrew Gray (talk) 19:37, 6 November 2019 (UTC)
Do we have a good approach for images about 3D objects, notably sculptures/statues? Frequently single perspective isn't sufficient, but one needn't look at the entire Commons category either. --- Jura12:00, 7 November 2019 (UTC)
Google Knowledge Graph displays multiple images, for instance type in "Billy Joel" or "Taylor Swift" and you get 7 images in the infobox. RAN (talk) 13:16, 7 November 2019 (UTC)
Restricting to one image is a logical choice. Once you decide to allow multiple images, there's really no limit to the number that you could add to a single item. Ghouston (talk) 11:09, 9 November 2019 (UTC)
Dumps as CSV-files
Hello,
I am not a programmer and dont know much about specific data formats. I personally dont have a program to open the file format of Wikidata Dumps. Is it possible to make the daily Dump accesible as a CSV-file. A few days ago I added Descriptions and some of them contain a qid in their Description. It wasnt easy for me to find them and correct them and I havent corrected all of them yet. The query times out and via the API I havent get more than I think 500 results. People who dont know much about programming often use Spreadsheets for processing data. Do you think there are ways to make Wikidata more Spreadsheet friendly. If you want that the motto of Wikimedia „Imagine a world in which every single human being can freely share in the sum of all knowledge." becomes real then I think Spreadsheet friendlyness here in Wikidata is important. At the moment not every one can use bigger amount of the data because not every one is a programmer. After Wikidata is more Spreadsheetfriendly the number of people who can use the data is bigger. I suggest to look that it is possible to get the data of a specific topic as a CSV-File and also the recent changes and the edits with a specific tag. When I get the data in a readable format then I can help create specific lists of it. If someone knows something about Macros in LibreOffice it were great if the one could help me create some Macros to make the list creation easier. -- Hogü-456 (talk) 21:45, 6 November 2019 (UTC)
@Hogü-456: If you want to find all descriptions in a specific format, you may query the wb_terms table at either quarry: (not suitable for huge number of results) or Toolforge.--GZWDer (talk) 22:05, 6 November 2019 (UTC)
I am regularly using spreadsheet for data cleaning/preparation. Usual workflow is:
write sparql
export results to tsv
open tsv in notepad
copy/paste results in spreadsheet
process and prepare data for quickstatement v1
copy/paste results to qs
run batch
The downside of that approach is that one should know sparql, but I don't believe there is technically viable solution that would allow you to edit 60M rows in excel, so you have to do some filtering. Regarding your specific issue, here is a draft query, that will allow you to fetch first NNN problematic descriptions. You can fix them, wait data will be replicated and re-run query. Obviously it has some false positives (like "Gemälde von Quentin Massys"), but you can easily filter them out in spreadsheet Ghuron (talk) 10:02, 8 November 2019 (UTC)
60M lines sounds doable in a programmer's editor like vim, and I sometimes edit TSV in such an editor. A 4K monitor helps. --SCIdude (talk) 15:04, 8 November 2019 (UTC)
If you are capable to use vim, most likely you are able to learn sparql. OP point was that we have people, who can work in excel, but has no clue about programming. Right now their contribution is limited to UI Ghuron (talk) 05:36, 9 November 2019 (UTC)
how to record complex "position held" situation ... ?
I found the following paragraph in a bio of Zoë Barbara Fairfield (Q27578052): "Fairfield's lengthy SCM career included being chair and then secretary of the London women's committee (1898), organizer and general secretary of the Art Students' Christian Union (1902-1909), a regular member and officer of the British executive (1909 to at least 1929), assistant general secretary for women for the British SCM (1909-1929), British representative at the WSCF Conferrence at St. Beatenburg (1920), and general secretary of the auxiliary movement (1929-1933?)." Is it okay to just add the statement Zoë Barbara Fairfield (Q27578052)position held (P39)officer (Q61022630)of (P642)Student Christian Movement of the United Kingdom (Q7627652), with the whole quote in the reference? The quote isn't available to data linking. I have been adding sketchy items (usually just a name) for "the London women's committee of the Students' Christian Movement" etc. etc.; if I did a proper job of it, I could spend days researching. This source doesn't go into details of what exact positions were involved in being "a regular member and officer of the British executive" and again, I don't have time to research it. My main problem is that I don't know how to record the exact job title for things like "assistant general secretary for women for Student Christian Movement of the United Kingdom (Q7627652)."--Levana Taylor (talk) 11:59, 9 November 2019 (UTC)
Add option to add comments to changes to items, similar to other Wikimedia projects
Dear all,
At present it seems (if i'm not mistaken) that one can effect a change to an item, but NOT explain etcetera this change in a comment which then shows in the History listing, like on all other Wikimedia projects. Of course there is a discussion page with each item, but it would be more practical to be able to review changes by reading the comments (if any) coming with the changes in the History of the item. (At this moment i refrain from making an (I think) useful change to an item, because there is no way to explain this to other users who might take issue. Perhaps the initial philosophy of Wikidata entailed, that comment and justification of changes would be superfluous here, but i would like to discuss this.) Enjoy the light if you can, Hansmuller (talk) 08:14, 9 November 2019 (UTC)
In some cases I wanted that option, too. For instance, when doing changes that to myself would have seemed weird at first I'd like to give a quick pointer for other editors like "this statement is now on item X" or "see discussion Y". Toni 001 (talk) 03:19, 10 November 2019 (UTC)
I wasn't exactly sure what you're asking, but have updated the item to reflect the name change - hopefully my edits are self explanatory as an example --SilentSpike (talk) 16:00, 10 November 2019 (UTC)
As far as I know Wikidata has no public deletion registry. If you want to be able to keep track of items you created it would make sense to register an account so that you can look into your contribution history. ChristianKl ❪✉❫ 19:11, 10 November 2019 (UTC)
Hey, We should not circles in our dependency graph of P279 (because it's a hierarchy). Running an graph analysis tool says these three dependencies should be removed:
I'm almost certain the second one should be removed, for the other two, I'm not expert enough ontology to say what should happen in those. Please take a look Amir (talk) 18:52, 9 November 2019 (UTC)
information resource (Q37866906) specifically says it’s an electronic resource, so I don’t think it’s a good choice here. “Document” is a subclass of four items (not necessarily a problem) and is matched to three concepts in the Getty AAT hierarchy. This suggests to me we haven’t properly settled on the scope of what a “document” is. - PKM (talk) 04:12, 10 November 2019 (UTC)
It looks like the first pair is using the dependency defined in a reference (which have conflicting views). Items for taxon names solve this issue by using "parent taxon" statements.--- Jura10:27, 10 November 2019 (UTC)
They have it from enwp, with reference a BBC article that states "There are genetic forms of the disease. In addition, some cerebellar ataxias can be caused by brain injury, viral infections or tumours." So enwp got it wrong, isn't it? --SCIdude (talk) 14:18, 11 November 2019 (UTC)
Add language to P1559 (name in native language)?
I discovered an error in Alulim (Q447370), which claimed that the native language of this personage's name was Sanskrit, instead of Sumerian (Q36790). However, when I attempted to correct it, Sumerian was not one of the permitted values. this Despite my attempts, I can't figure out how to add this value to the necessary field. Can someone either fix this, or explain how to fix it? (It might be preferable to show me how to fix it, since I'm finding several ancient languages not allowed here.) -- Llywrch (talk) 18:08, 10 November 2019 (UTC)
In order to decrease the size of what we store in caches we stopped storing the actual EntityUsage objects in ParserOutput and now just store minimal identifier strings (phabricator:T236749)
Only the existing languages and my spoken language were displayed. I did not find a way to create a field "arabic". Yug (talk) 18:15, 11 November 2019 (UTC)
@Yug: I ran into this problem a while ago. The solution is to go into your preferences under "Gadgets" and enable labelLister. Then there will be a tab at the top of the page, right next to "View History", labeled "Labels list". You can use the "edit" button at the bottom to add a label with an arbitrary language code (for example, "ar" for Arabic). Vahurzpu (talk) 18:32, 11 November 2019 (UTC)
I've come across a few possible properties, but find it hard to tell if there's a relational distinction between something being present vs just being name-checked. For instance, a character is actually present in a book, but if they say at some point that their favourite artist is Pablo Picasso (Q5593) then to me it seems like he is not actually present in the work, but is referenced. So there's a relation between both Picasso and the character to the work, but they're two different relations.
Name-dropping could be interesting for certain works (it seems to be a prevalent device in Hip-Hop). I think I would support an own property that is restricted to name-dropping of institutions, persons, brands, locations and similar entities.
As to the Picasso-case (I would not call it name-dropping in the strict sense) I would probably model it as in-narrative data: if there is an item for the character I would link from the character to Picasso via interested in (P2650). - Valentina.Anitnelav (talk) 10:58, 5 November 2019 (UTC)
Support I like that idea a lot Jura. It would allow us to clean up a lot of cases where "mentions" are confusingly put into "depicted by", "present in work", "named after", "main subject", etc. Moebeus (talk) 02:15, 6 November 2019 (UTC)
@Valentina.Anitnelav, Jura1: I considered proposing one, but struggle with determining to what domain it should apply. The musical work use case is simple, but it seems like there is desire for properties to be as generic as possible and I can see use cases for written works and audiovisual works too, but struggle to define how the property would apply alongside others such as P1441 especially if it is broadened to include non-fictional entities. --SilentSpike (talk) 13:30, 5 November 2019 (UTC)
present in work (P1441) can be already used on non-fictional entities, as long as they are part of the story (see for example Titanic (Q25173) which was approved on the property's talk page).
I think the domain could include all works. It should be made clear that 1) the entity should be a named entity (so not "grass", "sky", etc.) and 2) that a more specific property should be used if possible. If an entity appears in the story of a work (like Titanic (Q25173) in Titanic (Q44578)) present in work (P1441) should be used, "mentions" only if this is not the case (e.g. if a character mentions the Titanic in a dialogue - or if a rapper mentions the Titanic in a song). Also if a place is part of the setting of the work, narrative location (P840) should be used, "mentions" only, if it is - well - just mentioned (e.g. if a character speaks about this place or if a building is mentioned by the narrator as part of the scenery). If a creative work mentions another creative work in my opinion cites work (P2860) should be used. We should provide a complete list of alternative properties via related property (P1659) that should be taken into consideration before using the less expressive "mentions". - Valentina.Anitnelav (talk) 14:50, 5 November 2019 (UTC)
Personally, I think the main advantage of such a property would be that it would avoid that other more specific ones get cluttered with unrelated values. Maybe we need to create a few other more specific ones before creating this one. Any suggestions? --- Jura08:39, 6 November 2019 (UTC)
Of course they could, but this would avoid moving things around. It would be good to try to draft a comprehensive list of properties to use instead before we create this. --- Jura10:35, 6 November 2019 (UTC)
I agree, this was also something I had been pondering - for example, 911 / Mr. Lonely (Q39045786) has lyrics "mirror mirror on the wall" which alludes to Snow White and the Seven Dwarfs (Q134430). However, there's a complication there in that does it really allude to the film (where the actual line is "magic mirror on the wall") or to the original Brothers Grimm story (where it is "mirror mirror")? I expect there are a load of cases where something could be alluding to a work that has multiple versions/formats.
This is getting a bit offtopic, but in the German version of Grimm's Snow White the line is "Spieglein, Spieglein an der Wand"[6], which literally translates to "mirror, mirror on the wall". As a German-speaker I would thus suppose that it is a quote from Grimm's Snow White in translation, but it would be better to find a source that actually states that (why would you suppose that it alludes to the Disney version?). - Valentina.Anitnelav (talk) 10:07, 7 November 2019 (UTC)
Simply because culturally most people (these days) would first associate snow white with the Disney movie - including the original quote. However, I suppose it would still be in reference to the original story by proxy. In any case, you're right that it's a bit off topic and shouldn't prevent property creation. --SilentSpike (talk) 12:15, 7 November 2019 (UTC)
I think the label is fine, I would also support the immediate creation of above "mentions" property too (following your considerations re "named entity", etc.) if someone else would like to propose it - as I think I'm not the most well equipped to do so. --SilentSpike (talk) 12:15, 7 November 2019 (UTC)
I would take care of it during the weekend (this is not the easiest property to propose, given its history). But if you should find time to propose it: just go ahead :). You can take other proposals as a model and it can still be adapted to concerns later. - Valentina.Anitnelav (talk) 09:25, 8 November 2019 (UTC)
I think the label is too general. It's not immediately clear from the proposed label how this is different from "cites" or the reference part of statements in general. --- Jura12:18, 7 November 2019 (UTC)
I'm not sure it's possible to distinguish this via the label alone because it's a more general superproperty of "cites work". I think it just needs to be made clear that specific properties are preferable where appropriate. I suppose "references work" would make the use a bit more clear. --SilentSpike (talk) 12:28, 7 November 2019 (UTC)
Proposal
@Valentina.Anitnelav, Jura1, Moebeus: Since there's a lot of discussion above I've started a new sub-section here to direct your attention to my proposal along these lines: Wikidata:Property_proposal/mentions_named_entity. Please feel free to edit if you think there are obvious improvements/clarifications to be made. Also please add more examples if there are other possible types of work that this property could be used on (a film perhaps). --SilentSpike (talk) 16:50, 8 November 2019 (UTC)
What type of work would this apply to? How many such statements should we have? Most works have a person or place index should these all be included? --- Jura10:15, 10 November 2019 (UTC)
Some good questions - for which I can't say I have all the answers, but am glad to have the discussion and refine the proposal. I'll respond on that page for the sake of keeping proposal discussion contained and later archived. --SilentSpike (talk) 10:33, 10 November 2019 (UTC)
With "It would be good to try to draft a comprehensive list of properties to use instead before we create this." I had in mind that we do this before such a proposal. --- Jura07:36, 12 November 2019 (UTC)
Preferred single values
From time to time I come across statements where just one value is given, but which has nonetheless preferred rank. I don't think that this makes sense. Would it be useful if a bot would set all those single values to normal rank? Steak (talk) 18:06, 11 November 2019 (UTC)
Probably. They are a trap for the unwary who adds a second value with normal rank and doesn't notice the preferredness of the existing value. --Tagishsimon (talk) 01:39, 12 November 2019 (UTC)
Possibly there'd be edge cases of values imported from wikipedia to replace an existing value, where the importer didn't remove the 'good source' reference? The wrong citation would be removed. --Tagishsimon (talk) 01:42, 12 November 2019 (UTC)
Not too long ago, we made these "imported from" sources more detailed as users had trouble finding the corresponding information from the edit history.
A problem: how to record the source which was quoted erroneously by many secondary sources?
Wow, this is a bit of a complicated one. There are currently two items for French-born illustrators with the same name: Louis Huard (Q21555912) (1813-1874) and Louis Huard (Q3262203) (?-1842). Information about the one who died in 1842 is very scarce. The more I try to find him, the more I suspect he doesn't exist: it's just a false death date reported for the other one. I'm not the only one who thinks so, see here, which cites a number of authoritative-sounding sources, although I haven't been able to read any of them. And I think I found where the error originated, too: in 1848, in Siret's "Dictionnaire historique des peintres de toutes les écoles" there is an entry for Louis Huard which contains the date "*1842". Now, the asterisk means that that is a floruit date! Could someone have simply misread Siret, and their mistake has been repeated ad infinitum since? How should all this be recorded in WD? Levana Taylor (talk) 01:02, 12 November 2019 (UTC)
Merging Education in the Netherlands by municipality (Q56751655) and Education in the Netherlands by city or town (Q8407505)?
@Joshbaumgartner:
Since I believe that the topics "Education in the Netherlands by municipality" (Q56751655) and "Education in the Netherlands by city or town" (Q8407505) covered a similar scope, I attempted a merge of the entries but found that there were two separate commons categories.
There was a discussion about merging the Commons entries at Commons:Commons:Categories for discussion/2019/09/Category:Education in the Netherlands by city and the entries have been merged. At the end I received the suggestion that there should be further discussions before merging the wikidata entries. What further steps should be taken before I move forward with an attempt to merge these entries?
That's not a valid value for SBN author ID (P396) as the contraint is defined. Maybe you mean “IT\ICCU\VEAV\037458”? Maybe the interface blocks IP editors from making constraint violating edits. In any case even after my edit the ID doesn't resolve on the website. ChristianKl ❪✉❫ 08:47, 13 November 2019 (UTC)
Is there a property for museums where an artist has had an exhibit?
I am quite new to working on Wikidata, and appreciate your help. I am trying to enhance the Wikidata entry for an artist (William B. Schade) whose article I worked on in Wikipedia. I would like to add a property for places where his artwork has been exhibited (solo exhibits), but haven't found the right property with the searches I've done. I did find Exhibition History (P608), but that is clearly for works of art, not for artists themselves. I also see Has Works in the Collection (P6379). I assume there is such a property and I just haven't found it, but perhaps not. Thank you! TrudiJ (talk) 10:14, 12 November 2019 (UTC)
I would create an item for the exhibition(s) as art exhibition (Q667276) with <main subject> = William B. Schade, and then list each exhibition as a significant event for William B. Schade. Individual artworks can be linked to the exhibitions if you want to go that far. - PKM (talk) 21:48, 13 November 2019 (UTC)
Proposal to structure/describe templates through Wikidata schema
At WikidataCon 2019 (Q42449814) there was a breakout session where we discussed ways to use Wikidata schema to better structure templates as well as the mappings between template fields and the relevant Wikidata property (Q18616576) where one exists. Currently there are a few different efforts already working this - Harvestbot templates, DBpedia, etc. - however this information is stored across various locations and formats. This new schema would help coordinate efforts and increase visibility by putting this information in a central easily accessibly place - i.e. the Wikidata item for the template.
I've written up the main takeaways from the session as a proposal for new schema and wanted to open up discussion on the high level design to the broader community before submitting individual property proposals. :)
By schema I mean new properties and how to use them - for the latter I think creating a ShapeExpression for these templates would be a perfect way to formalize these semantics.
This is a related but parallel effort to Wikidata Bridge. The main difference is scope, Wikidata Bridge will allow users to edit Wikidata-driven infoboxes directly on Wikipedia whereas this effort will initially aim to describe existing semantics of old-style (non-wikidata) templates. Once Wikidata Bridge is launched the label-property mappings for these new templates could also be described using this schema for consistency. ElanHR (talk) 16:19, 13 November 2019 (UTC)
One issue that may or may not be relevant, depending on exactly what you're thinking of doing, is that a single Wikidata item may sitelink to templates on several different Wikipedias and/or sister projects, that may correspond in terms of subject, but not necessarily in terms of structure and arguments. (But where the sitelinks between them may be valuable to maintain nevertheless).
So any links from Wikidata items to your schemas (once we have that ability) may require a large number of applies to part (P518) = "xyz-wiki" qualifiers; which may impact on the readability of the item for the template. Jheald (talk) 10:56, 13 November 2019 (UTC)
Papers with pages in Wikispecies, not linked in Wikidata
There are a large number of scientific papers which are documented on Wikispecies, in the Template: space (e.g. species:Template:Kayaalp, et al, 2012, which I just matched to Q44024329), and which either do not yet have Wikidata items, or have Wikidata items with no interwiki link to the Wikispecies template. Some of the Wikispecies templates have DOIs or other identifiers, but some do not. The data is largely unstructured, but perhaps scrape-able. Most of the Wikispecies templates for papers are linked to the Wikispecies pages about the author, which are almost always linked to Wikidata items.
It makes sense to link these to the items for the papers rather than usual template item. You could try to use harvesttemplates on the DOI template. --- Jura17:36, 13 November 2019 (UTC)
Linking to items for papers is precisely what I'm talking about, as can be seen from my example. I'm not clear how harvesttemplates will help in the case of papers on Wikispecies with no equivalent Wikidata item, nor for such papers that are not linked to an existing equivalent Wikidata item. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits22:39, 13 November 2019 (UTC)
It would need to be done in several steps: create items for all pages with such a template. run Harvesttemplates to import identifiers, delete default labels, run one of Magnus' tools to complete the data, merge potential duplicates. --- Jura23:08, 13 November 2019 (UTC)
different properties used on items that are instance of (P31)writing system (Q8192) (or its subclasses), each with an example trio { writing system + property + value }.
corresponding items, with their immediate instance of (P31) classes.
I'd be very grateful if anyone could have a look at these; I'm a bit pushed for time just at the moment to properly look into it myself. Jheald (talk) 02:03, 12 November 2019 (UTC)
@PKM: Thank you so much for looking at these. Here's a query for the current most common classes in the sub-class tree https://w.wiki/C3i though I don't know if there are good tools to see it in tree form.
If there are modelling nuances here (eg how to model typefaces vs scripts vs symbol-sets; how items for individual characters should fit in; shape of the subclass tree; listeria pages for most common properties, etc; etc), then I wonder if it would be worth making some WikiProject pages to document best practice? Jheald (talk) 11:12, 14 November 2019 (UTC)
I'd be delighted to participate in the documentation of best practices for writing systems/alphabets/typefaces if other folks are interested in working in this area. There are several places where we need to build consensus - for example, distinguishing "alphabets" and "writing systems", or modelling "notional" classes of typefaces (sans serif, humanist) vs. names of those classes in specific classification systems. - PKM (talk) 19:33, 14 November 2019 (UTC)
Updating Swedish-speaking Finns in Wikidata with Wikipedia categories as source and reference
As part of Projekt Fredrika, I'm working on improving the coverage of Swedish Finland on Wikipedia and Wikidata, in Swedish and other languages. Swedish speaking population of Finland are today a 5% minority in Finland - they speak Swedish as their mother tongue (second official language of Finland; monitored by the government, but registered privately), are Finnish citizens, and can also be considered an own cultural minority.
On Wikidata, there are at the moment only 17 people with Swedish-speaking population of Finland (Q726673) as ethnic group (P172). Out of all Finnish citizens, only 57 have Swedish as their native language. I'd like to enrich this using the list of 604 people within the English Wikipedia category Swedish-speaking Finns, and later use the same category in other languages.
Analyzing the 604 people within the Swedish-speaking Finns category:
Citizenships (P27) is missing for 48 people. I have figured out the correct data to update people to based on their Wikipedia article and when people lived (modern Finland, Dutchy of Finland part of Russia, or pre-1809 part of Sweden). This should not be controversial to update.
Native language (P103) Swedish (Q9027) is missing for 574 people - I would say that updating their native language to Swedish will be correct in 99,5% of the cases. There might be some outliers that have "converted" and considered to have become a Swedish-speaking Finn later in life and their native language is thus something else, but that is the type of exceptions that will probably get corrected later when using more data sources to update people's information on Wikidata. For the people that were not missing native language, I have reviewed the existing data manually already.
For Ethnic Group (P172), Swedish-speaking population of Finland (Q726673) is missing for 595 people. I would say updating these 595 is pretty clear, considering they have for one or another reason been considered and put on the Wikipedia category Swedish-speaking Finns in the first place. Being Swedish-speaking Finn is clear in most cases, and subjective in very few cases.
After doing these updates and practising this process, I would do the same for the equivalent category lists for other Wikipedia languages - primarily the Swedish and Finnish lists and possible others - using them as source and reference.
I have been practising the use of PetScan, Open Refine and QuickStatements to do these types of large scale updates.
Much of my proposal is based on how similar properties for IDs are used at the moment. And as I've written on the talk page: "Though many of these could be added to the subject item of the property, these are often non-existent and I believe it would be easier for a future Wikipedia template to use these IDs if they contain all the information." --Adam Harangozó (talk) 15:26, 14 November 2019 (UTC)
The question is not what we suggest, it is not for us to suggest anything. It is what is meant by a species novum. Ask a professional what is meant. Thanks, GerardM (talk) 19:54, 16 November 2019 (UTC)
Both Geni and Familysearch flag what appears as logical errors (mostly typos), maybe we should be doing the same. Geni just started this week. Can someone run a query to find people who died before they were born? I think I can come up with a few more simple tests of error rates. Every data set is prone to errors, and even correcting errors can cause more errors. This would be one objective way to see our error rate. Has this been done already? Do we rerun it from time to time? We did something similar a few years ago to look for doppelgangers, multiple people born and died on the same day. We merged the true synonyms and flagged the actual birth-death doppelgangers. Do we have a Wikidata:Data_integrity page to track these type of searches and the results? --RAN (talk) 15:29, 15 November 2019 (UTC)
Excellent, thanks! Do we have "people over 120 years old" which would be another red flag. I will keep track of them at Wikidata:WikiProject Genealogy since they concern genealogical data and the people there have the resources to find the correct dates. --RAN (talk) 17:03, 15 November 2019 (UTC)
That is exactly it, thanks! Wow, that is a lot of obvious typos. Some of the errors come from other poorly controlled data sets, and we imported the error, but I seem to be able to correct them with other sources. I noticed that several of the entries came from VIAF and LCCN. They need to be merged once they recognized the error and realized they already have a record with the correct death/birth date. VIAF appears to be monitoring our records for duplicates and other errors. The bulk of our own errors are simple transpositions of numerals in a year or the truncation of a digit when cutting and pasting. --RAN (talk) 20:51, 15 November 2019 (UTC)
I have corrected over 200 in the two lists by finding a source for the birth date or death date. Most were typos on our end, like typing 1963 for 1863, and occasionally it was a typo by one of the authority files we imported. A few were errors conflating father and son with the same name, and using the birth date of one with the death date of the other. I kept and deprecated the bad date if it is still displayed at the source authority entry. Another big source of errors is sloppy matching of a person of the same name from IMDB and VIAF and LCCN only because the name matches, some were not even matching names. Can anyone think of a way we can flag the people over 120 that are not true supercentarians, that have been reviewed and are insolvable for now, so we can concentrate on the ones that can be fixed? Look at Andrew A. Lipscomb (Q4756164) and how we handled that he had a doppelganger so that people in the future are aware that they are not the same person. Any ideas? --RAN (talk) 18:55, 16 November 2019 (UTC)
Just check if the date of the death is present in the item: after that if people assume that ghost can has a social media account, that's their problem. Snipre (talk) 10:07, 17 November 2019 (UTC)
stated in (P248) the set of shapefiles -- they don't mention the settlement in question, nor give coordinates or boundaries for it, just boundaries for the (historical) administrative entity it has been calculated to fall into. This is particularly relevant given that some of our coordinates may not be quite right: the statement is an inference based on them, that might be wrong; not a statement made outright in any source.
inferred from (P3452) the shapefiles would be good -- but P3452 says there should be a statement on the corresponding item, that the present statement was inferred from
based on heuristic (P887) can be used to indicate an inference -- but its value should a the item for the heuristic generally, not a specific data source.
based on (P144) is a main-statement for use on items for derivative works, not a sourcing property for statements
@Snipre: Firstly: there's no way in SPARQL to ask whether a point is within a shape. Secondly, the shapes aren't on the system anyway. Thirdly, we have the P131 property, and it ought to be populated as comprehensively as we can. Fourthly, one wants the data to be available so it can be extracted readily, and so one can record the evidence for what will be the corresponding category relations going in on Commons. Also, one wants to be able to note when the inferences from the shapefile differ from (or augment) the P131 values that may have been gathered from other sources.
For all of these reasons, it's useful to create the statement. The question is how its source should be recorded. Jheald (talk) 20:20, 15 November 2019 (UTC)
@Jheald: You completely forgot one thing your new statement will be based on the shape and how do you will link your statement with that shape ? If the shape of area is well defined and well accepted, no problem but in case of disputed territories, your inference is not obvious and a description of the shape has to provided. If you can't provide the shape information in the statement so this is original work and not an inference, because you can't ensure that someone else can find the same results as you. Better create a dataset and save it somewhere in the web, and used the reference structure to refer to it. Snipre (talk) 13:00, 16 November 2019 (UTC)
@Snipre: It's exactly how to indicate which set of shapefiles the inference was based on, that is what I am asking how best to do. See below. Jheald (talk) 13:29, 16 November 2019 (UTC)
I think based on heuristic (P887) was created for this. Not sure where "FIBA player ID (P3542)" would come in. I guess you wanted to list another property.
It was created for a value called "personal name". I don't think this is much different from "coordinates and shape file" that could be used with your sample. --- Jura09:33, 16 November 2019 (UTC)
These are obsolete French terms for the intercardinal points. The article say they are still in use as sailing terms. Frwiki does not have separate articles for the intercardinals otherwise (they are briefly defined within the corresponding disambiguation pages). I wouldn't have them as article on frwiki myself, but I don't think a merger is appropriate. Circeus (talk) 23:07, 17 November 2019 (UTC)
Yes, people have been linking to the generic name instead of creating an entry for the actual person. We had a !vote and the consensus was to remove the generic links, and if you have enough interest create an entry for the real person. --RAN (talk) 20:41, 17 November 2019 (UTC)
I just corrected about 200 bad data entries by hand that caused a person to have died before they were born. A lot were from the same data entry batch from 9 October 2017. Look at Richard Poulin (Q20639668) where an erroneous date-of-death was added for the person on 9 October 2017 for a completely different person named Emanuel Candidus. I have corrected the ones that caused a person to die before they were born, but how many other erroneous ones were added that did not raise an obvious red flag? Can someone check? We can automate it to look for the name of the Q record does not match the name for the CANTIC entry for date-of_birth or date_of_death. --RAN (talk) 00:52, 18 November 2019 (UTC)
CANTIC as ref for DoD, for items with a CANTIC ID, pulls up a bunch of records where the DoD ref is a person other than the person the item is describing:
Lack of interest of the supporters? Good thing a property creator found it and transcluded it into the relevant pages, otherwise it would have been completely forgotten. --- Jura09:40, 19 November 2019 (UTC)
What is the purpose of this list? Is it used? Why are there no definition of town or village there? How can it be improved if the bot overwrites changes?--So9q (talk) 22:23, 12 November 2019 (UTC)
Classification with Wikidata invented limits will not work. We have to accept that each country/culture/language has its own classification of human settlements and this diversity must be reflected in Wikidata. --Pasleim (talk) 08:07, 12 November 2019 (UTC)
Sweden, Denmark, and Norway can't even agree on this, but the statistical tools they use are somewhat similar. The common idea is that a populated area exist where people live within some distance from each other. The area will then be of some size and some population. Often it is used more than one set of limits, which gives rise to townships and cities. In Norwegian it is called “tettsted” og “bymessig bebyggelse”, in Sweden they have “tätort”. The statistical definitions seldom follow historical boundaries, and they also tend to grow into larger areas over time. See for example w:Fredrikstad and w:Sarpsborg which has grown into Fredrikstad/Sarpsborg (Q3355000). Jeblad (talk) 09:22, 12 November 2019 (UTC)
My idea was to have our own classification beside the one the countries do themselves. So if an area in sweden is stated as instance of urban area of sweden but has a population over 20,000 'we decide to state that it is a city in our definition in addition to the first mentioned. This enable us to do meaningful comparisons like in the example queries across borders if countries with different definitions of human settlements. Right now that won't work because e.g. Gävle is not stated as any of the above mentioned subclasses. Alernatively we could deprecate all the above subclasses and have any settlement as instance of human settlement and in SPARQL sort them by size or whatever when we do queries. We could also extract all buildings inside the OSM relation defining the settlement and use that as a unit of size (example overpass query for Sundsvall).--So9q (talk) 09:46, 12 November 2019 (UTC)
That was not what I suggested. Having a new property for stating the number of buildings within the area is a statement just like population. I think it could be nice to have as we would be a unique source for that information.--So9q (talk) 06:03, 13 November 2019 (UTC)
Every city is also a human settlement, so there's no need to explicitely say that cities are human settlements for being able to query all settlements with a given population. ChristianKl ❪✉❫ 17:55, 12 November 2019 (UTC)
I know that. My proposal is to either get rid of the subclasses mentioned above or agree on the population limits for them.--So9q (talk) 06:03, 13 November 2019 (UTC)
My point was that there's no value gained by doing that. On the other hand you lose the ability to store how a settlement is classfified by the people who live in it. That's especially problematic for settlements where we don't know the population but do know how people describe it. ChristianKl ❪✉❫ 08:41, 13 November 2019 (UTC)
Interesting point. But this makes it meaningless to make comparisons across countries because you compare what people arbitrarily call the place they live but that does not yield anything useful when doing SPARQL queries IMO. Personally I don't care much what people call their living place, its simply not that interesting a datum to me. The size in comparison to other cities in the world on the other hand gives me perspective and is a very useful datum to me. If you want a property for what people "call" their settlement I suggest you invent a new property for that purpose.--So9q (talk) 19:13, 13 November 2019 (UTC)
Wikidata doesn't exist to only serve your usecase and answer question you care about. It exists for a variety of different usecases. For historians who deal with settlements where no population numbers are available it matters whether the sources describe the settlement as city or town. If you care about the population and make your query about population property. ChristianKl ❪✉❫ 10:54, 14 November 2019 (UTC)
Thanks for pointing this out. It would be a bad idea to loose data this way. Also I think it is a bad idea to continue with our current taxonomy for human settlements. See Andrews proposal below.--So9q (talk) 11:17, 18 November 2019 (UTC)
Far easier to say "settlement", or use an appropriate local taxonomy, and let people figure out their own classification by population, rather than try and force our own one. (We should perhaps also reconsider whether we really want "big city"). Andrew Gray (talk) 18:37, 12 November 2019 (UTC)
I'm in favour of removing "big city". But you do realise it does not make any more sense than the others as long as we do not define what we mean by city versus town versus village. I think we have to first define them to meaningfully be able to distinguish them.--So9q (talk) 22:23, 12 November 2019 (UTC)
While there are a few cases where Wikidata engages in creating orginal content, generally Wikidata tries to record what other sources say about a subject. When we say "city" instead of "village" that means that there are sources that describe this as a "city" instead of describing it as a "village". ChristianKl ❪✉❫ 08:41, 13 November 2019 (UTC)
In this case, fixing those queries to use "human settlement" as the top-level item in the hierarchy would return all the Swedish ones (and everywhere else that doesn't use "city"), and then adding a size filter would return only the ones above 100k or 20k or other preferred thresholds. This would be a much more efficient solution than trying to invent and enforce our own taxonomy. Andrew Gray (talk) 12:44, 14 November 2019 (UTC)
Interesting, then you just proved my point and provided a valid reason for us to classify settlements according to size of population. Settlements where we don't know the size of the population could have their own item as subclass of human settlement.--So9q (talk) 17:59, 14 November 2019 (UTC)
@Jheald: I do appreciate that there are definitely some tradeoffs here, but I think we're going to massively confuse people if we impose a data model that simply doesn't map onto what so many places use. We used to have this with the first shaky attempts at a GND-driven top-level taxonomy where everything was one of a few different highly specific things; we rapidly abandoned that as unworkable. I think imposing this model is going to be a bit of a backwards step, if it's possible to instead do something like streamlining the hierarchy below "human settlement" to make it more efficient.
On the other other hand, we could consider a human (Q5) style taxonomy - everywhere that's a settlement uses a single instance-of, with no kind of subdivision, and we use a separate property to describe its legal form. Querying for "population in size range X" and/or "place that has some kind of legal status as a city" would presumably be a lot more streamlined at that point. Andrew Gray (talk) 20:02, 14 November 2019 (UTC)
There's no benefit from adopting a human (Q5) style taxonomy here. The query for the population size wouldn't change at all. If I read in a 15th century document about a settlement that's a city, then I don't know whether that's a city in the legal sense or in another sense. ChristianKl ❪✉❫ 15:29, 18 November 2019 (UTC)
In the U.S. the terminology is almost entirely about form of government, not about size, and varies from state to state. Washington state has some "cities" (e.g. Ritzville) with less that 2,000 people, and conversely at least one "census-designated place" (no corporate entity or government of its own), White Center, Washington|White Center, with about 14,000. - Jmabel (talk) 01:29, 13 November 2019 (UTC)
Interesting. Anyway based on population it would be entirely correct IMO to state a settlement of 14,000 people as a town in the wikidata meaning of it. If you have a special way of defining administrative cities in the U.S. you can create an item for that, see e.g. Serbian city (Q37800986)--So9q (talk) 19:13, 13 November 2019 (UTC)
No, you cannot set "arbitrary" limit, any data - especially such important one like here - need references. Explanation of why you want/need such limit would be welcome too. In France, we have no such classification so it's unusual for me to see it this one (especially as some municipalities can have 0 inhabitants and a municipality with 1900 inhabitants is not a city). Cdlt, VIGNERON (talk) 16:16, 14 November 2019 (UTC)
Yes, it also becomes inconvenient when settlements change in population. If a settlement had a population of 19999 last year and 20000 this year, you'd really want to create separate items for the "town" and the "city" since they are apparently different things. I'm not a fan of start and end dates on instance of (P31) statements. I think it's much preferable to declare it to be an instance of human settlement (Q486972) with qualifiers on population (P1082) statements. Ghouston (talk) 21:31, 14 November 2019 (UTC)
Thanks for pointing this out with clear examples. :) I agree that my solution is not a good one. I like @Andrew Gray:s proposal above to switch to a flat taxonomy and indicate the legal form (as you and @ChristianKl: argues for keeping separate from population size) in a separate "legal settlement status" property. WDYT?--So9q (talk) 11:17, 18 November 2019 (UTC)
A form interface to run some basic queries, particularly people searches???
Hi. A search for William Dawson brings up many hits, especially as we have raw imported some databases. Trying to find a "William Dawson 1877" (for b. 1877) is not a workable search as we don't search the item fields.
I know that such a query can be run in the query service, though some of us aren't search competent, and honestly, I just want the capacity to run simple searches quickly, and not have to faff around with query syntax.
Has anyone put together a form query interface so we can do "people searches" based on a combination of:
name (main label, personal name, family name, birth name)
birth year
death year
place of birth (small cascade of place hierarchy)
place of death (small cascade of place hierarchy)
occupation (maybe cascade, or something with field of occupation)
This is so if the person already exists that I can link to them for an article added, though could just as readily be for an actual person page created at another wiki. — billinghurstsDrewth01:08, 17 November 2019 (UTC)
I would hope that something like this would not be requiring a user to have to dig up property numbers. I am looking for non-technical access, not making people have to dig through our technical jargon. — billinghurstsDrewth21:44, 17 November 2019 (UTC)
We do search the item fields. If content is string-based statements those get indexed for the search. If you for example search "William Dawson 1942" you will find that scientific paper that contains "serial ordinal 1942". The problem seems datetime fields are not properly indexed. Fixing the search so that it indexes the years shouldn't be too much work, and it would make sense to create a ticket for that.
Apart from that it would be possible to have a more elaborate search system, but that likely takes a lot more work then simply fixing the issue of datetime values not being indexed properly. ChristianKl ❪✉❫ 10:55, 18 November 2019 (UTC)
Split dam and reservoir
I am looking for a good way to split items they are for a dam and the reservoir created by the dam. Now it seems to be nearly always with one item with dam (Q12323) and reservoir (Q131681). Especial for commons it would be good to split this and for other properties it would be good to do this to. The problem is how to link these to items and where to link the articles they describe both. --GPSLeo (talk) 14:41, 17 November 2019 (UTC)
Just use has_part, we have been splitting church into church_building and congregation and cemetery the same way. We split because people are buried in the cemetery, not in the church. The congregation may have been housed in mutiple churches over their histories, as each old church burned down. Sometimes the old church building is in a historical registry but the new one isn't. Splitting is a good idea. See Kingston Presbyterian Church (Q73331165) --RAN (talk) 20:34, 17 November 2019 (UTC)
Yes. Or make a new value along the lines of "dam and reservoir complex". (I'm sure I've seen such a thing, but I cannot find it.) And then has part / part of are your friends. --Tagishsimon (talk) 16:49, 18 November 2019 (UTC)
Reason for no/unknown value
We have "reason for deprecation" I would like to see "reason for unknown/no value", or split it into two items. For instance we have no_value for place_of_burial for a number of reasons like "body donated to science" or "cremation" or "lost at sea" or "war casualty" or many other reasons. See list of Wikidata reasons for deprecation (Q52105174) --RAN (talk) 21:01, 17 November 2019 (UTC)
Panandâ, a mobile app powered by Wikidata (and Wikimedia Commons), won the top prize in the App for Social Good category in the Android Masters 2019 competition organized by Google Developer Group Philippines. Eugene, the app's developer, recently gave a lightning talk about the app at WikidataCon 2019.
@Wostr: I'm guessing the problem is the simolecule.com site is not quite accepting all the URL encodings. The default Wikidata UI should work for this. The wikidata-externalid tool acts to UNDO encodings, so it's not what you want here I think. Do you have any more detail about what the default UI URL is doing wrong? Maybe we need a phab ticket for it? ArthurPSmith (talk) 18:13, 18 November 2019 (UTC)
@ArthurPSmith: the problem is that formatter URL (P1630) in isomeric SMILES (P2017) uses values that are not UrlEncoded. Isomeric SMILES usually have some /, # that can broke the URL. In Wikipedia or other Wikimedia project I can use a parser function urlencode — then instead of a broken URL like the one in Q32089#P2017 I get something useful [9] — but I don't know how to do something similar here. Wostr (talk) 18:23, 18 November 2019 (UTC)
@Wostr: I believe the Wikidata UI automatically urlencodes the identifiers before substituting them into the formatter URL. Have you tried this, just enter the identifier in its natural state with all the /, # etc. and see if it works? ArthurPSmith (talk) 18:41, 18 November 2019 (UTC)
@Wostr: I have no idea - but I'm not seeing any link at all, are you seeing a link? What does "not work" mean in this context for you? It looks to me like something's fundamentally broken with the process for linking with formatter URL's, but maybe that's just affecting me at the moment? ArthurPSmith (talk) 20:59, 18 November 2019 (UTC)
@ArthurPSmith: yes, I see a link as I always have. The link is:
@Wostr: Ahhhh! Now I see the problem - this property is a String property, not an External ID. That means the Wikidata UI is not what is giving you the links, it's coming from a javascript gadget you must have running (and which I turned off) - I think it was an "authority control" gadget? Anyway, IF this property was an external id property I think it would indeed work. Maybe you can contact the developers of the gadget to see if they can fix, or maybe (if justified) we can change this property to be an external id? Or get some other fix from the developers? ArthurPSmith (talk) 21:09, 18 November 2019 (UTC)
@Wikiourembaya: It looks like the templates and modules that readily extract the WD data are not present at w:nqo:. You will need to find someone who will work with your community to get those components brought over. I don't see that "Special:Import" is configured to allow for the easy import of templates. — billinghurstsDrewth21:55, 17 November 2019 (UTC)
If your community agree (and you should discuss there first), then you can create and use Template:Databox. The whole (easy) procedure is explained on the page and you can ask me if you have questions. But your community first need to agree to use templates based on Wikidata. --Harmonia Amanda (talk) 12:44, 18 November 2019 (UTC)
can someone please update the Site Wikidata:Statistics and is it possible to use the daily dumps to get the Number of Descriptions, Labels and Alias per language. The site of Pasleim for that is not up to date and that because the query times out. -- Hogü-456 (talk) 17:43, 17 November 2019 (UTC)
Hello,
Can you tell more about your usecase? What kind of data do you need, at which frequency and how do you want to retrieve it? Depending on the answer, some tools may be more fitting to your needs. Lea Lacroix (WMDE) (talk) 12:49, 18 November 2019 (UTC)
I want a overview about the number of Descriptions, Aliases and Labels added updated dayly and I think the page Wikidata:Statistics is a page what some people visit and so the information there should be up to date. The page is important because of the number of items per topic. Pasleim had a statistic for number of descriptions updated every week but the query for that times out and so my idea was to use the daily dumps and count there the numbers of descriptions added. For that I want to use a Spreadsheet. I think the information what happens in a edit is there. In the recent changes I can see what kind of change happened. I dont know how precise the information is. If you know a tool I can use for it then I would use it, when I understand how. -- Hogü-456 (talk) 20:05, 18 November 2019 (UTC)
ARL white paper on Wikidata
Library of Congress blog post on integrating Wikidata into authority files
Library of Congress reports on ongoing bulk loads of Wikidata identifiers into authority files
Slides from Wikidata for Librarians Workshop at UC DLFx 2019
Wikimedia and Libraries User Group
"Creating structured linked data to generate scholarly profiles: a pilot project using Wikidata and Scholia" by Mairelys Lemus-Rojas and Jere D. Odell, 2018 – The preceding unsigned comment was added byUtl awong (talk • contribs) at 20:21, 18 November 2019 (UTC).
I notice they incorporate my corrections here at Wikidata into LCCN after a month or so, I would love to know how often they check against us for errors and what the process is. Does anyone know? --RAN (talk) 20:25, 18 November 2019 (UTC)
Since editor-in-chief (P5769) seems to be intended for exactly this usage, is seems like the most specific way to do it, and would also be easier to query, since it doesn't require qualifiers. There's nothing to stop somebody adding the position to the person's item as well, however. Ghouston (talk) 07:49, 11 November 2019 (UTC)
PLOS ONE Editors (Q63256335) seems to have been created to used as an author, and hasn't been linked to individual editors. I think this would be a non-standard method, and editors linked in this way wouldn't show up in typical queries. Ghouston (talk) 02:41, 19 November 2019 (UTC)
Same if I change my language in preferences. As the label exists in all these languages, I can not understand why it does not work. Pinging User:Jmarchn as initial reporter. --Vriullop (talk) 15:44, 18 November 2019 (UTC)
Make our global search also find lexemes by default
I learned today how to enter lexemes. Unfortunately I could not find anything when trying to link 2 lexemes via translation (P5972) which was quite bad, because then I had to remember or copy strings like this one around L222600-S1 or remember it.
I therefore suggest that our global search include lexemes by default. Mark them clearly as lexemes in the result to avoid confusion. WDYT?--So9q (talk) 12:46, 18 November 2019 (UTC)
Hello,
Thanks for mentioning this. I think there are two different issues here:
currently, our search service cannot provide suggestions for different namespaces in the same time (suggestions only list Items - if you're typing the name of a property in the search box, you won't get a suggestion list). This issue is known but quite complicated to solve. In the meantime, if you're looking for a Lexeme, you can type "L:word" in the search box, then type Enter, and the search results page will show results.
currently, when adding a statement where the value has a data type Sense, it is not possible to look for the list of Senses by typing the word. One needs indeed to type or copy the ID. This is also a known issue and part of the future improvements of the Lexemes interface.
Another issue is that "content pages", which seems to be the default search, includes main and Property namespaces but not Lexeme. Peter James (talk) 13:52, 18 November 2019 (UTC)
Apparently, search isn't optimized to search all three by default. (so don't activate it in your user configuration).
A very lightweight WD contributor, I sometimes correct coordinates of places. I notice that there is no Locator-tool like the one I often use in Commons. Also I don't see how to paste coords from a source. Am I failing to see the right way, or is this feature not yet added?
– The preceding unsigned comment was added byJim.henderson (talk • contribs) at 23:57, 18 November 2019 (UTC).
For the UK, my process tends to be to follow whatever coords we do have through GeoHack to find the place on the Ordnance Survey maps at streetmap.co.uk, then use that website's "convert coordinates" feature, then copy-and-paste to Wikidata (and en-wiki), generally trimming to 4 decimal places. But it's true, that is quite an all-round-the-houses approach. And only works for the UK. Jheald (talk) 12:02, 19 November 2019 (UTC)
Anyone want to help fix errors reported at Wikidata:Database reports/unmarked supercentenarians. Most of the errors are from importing "flourished" or "active" dates into the fields for birth and death. Others are just typos by us, or from the original VIAF file that have been already fixed on their end. If you recognize it as a flourished error, delete the birth and death fields and migrate the flourished date into the "flourit" field, I generally use the flourished date from VIAF. Another common error are presumed typos in the source data, see how I handle it here: Johann Christoph Streiff (Q71957610), several non VIAF data sets have a large number of uncorrected typos. I already corrected about 400 errors at Wikidata:Database reports/items with P569 greater than P570 mostly caused by typos like imputing "1785" as "1985" when retyping the number from VIAF or caused by reversing the birth and death dates. --RAN (talk) 14:18, 19 November 2019 (UTC)
Hi, we’re planning a data-ingest for the WikiProject Performing arts. There are currently some concerns about the data maintenance. Is there a “best practice” to handle updates to the data?
The following questions are unclear;
What happens, if the same data is updated in the source and on Wikidata? Can they be synchronized?
If a second ingest (with mostly the same data, only minor differences) is done, will the data on Wikidata from the first ingest be overwritten?
Can the ingested data be supervised (to be notified if someone on Wikidata updates an ingested item)?
Thank you in advance
– The preceding unsigned comment was added byVoget5 (talk • contribs) at 17:03, 19 November 2019 (UTC).
If there is new information, you can just add that. If the old is found to be incorrect, it gets "deprecated rank", see Help:Ranking.
This means old data shouldn't be overwritten.
If you want to follow what's updated on Wikidata, you can download/query the relevant items periodically. --- Jura19:49, 19 November 2019 (UTC)
Request to review some constraints for P6594
The Guggenheim Fellows ID property includes property constraints that might not be necessary for this property to be assigned: gender, date of birth, occupation, country of citizenship, place of birth. The resolving fellows profile pages do not include this information. Can this be reviewed somehow? – The preceding unsigned comment was added byRolery02 (talk • contribs) at 17:15, 19 November 2019 (UTC).
I have decided to block LargeDatasetBot (@GZWDer:), perhaps the largest source of data ingestion to Wikidata recently, for a period of 3 days, pending some closure regarding issues that the Wikidata Query Service has been having, not just in terms of 10-12 hour lags on the query servers but also due to a number of statistics regarding the service suddenly becoming unavailable. (Some of these have Phabricator tasks, while others do not appear to have them.) Other admins may rescind this block if they believe that the LargeDatasetBot does not primarily contribute to the problems afflicting the Query Service.
Is there reason to believe that the rate of new items is the issue for the Query Service instead of the number of queries that are made to the Query Service? ChristianKl ❪✉❫ 19:07, 13 November 2019 (UTC)
If I remember correctly, what hurts WDQS the most is edits on large items (even if the diffs are tiny). The ones that are happening on items about scholarly articles with many authors, such as https://www.wikidata.org/w/index.php?title=Q56489575&action=history, are likely to be the cause of this. I think it would be good to ask Simon Villeneuve to stop working on these big items (also notifying ArthurPSmith who maintains the tool, which is more economical in edits than the previous version based on QuickStatements to be fair). It would be good if Smalyshev (WMF)'s concerns about the suitability of this data in Wikidata were listened to: the community should take action on this, either by deleting these items, somehow enforcing that they are not edited often, forbidding to store more than a certain number of authors as statements… − Pintoch (talk) 19:44, 13 November 2019 (UTC)
Wasn't there supposed to be a maxlag adjustment to account for WDQS update delays? I don't think Simon's edits could be the (sole) cause; they are only 1-2 per minute at most, and there are long pauses between batches. ArthurPSmith (talk) 20:01, 13 November 2019 (UTC)
@ArthurPSmith: Yes clearly, lag is due to a combination of things, it's always the overall querying and editing activity that matters. But if someone from WMF clearly states that we are using the platform to store data it is not designed to handle, I think we should react to that… − Pintoch (talk) 20:23, 13 November 2019 (UTC)
We should indeed react, ideally by encouraging someone from WMF to work on whatever adaptions are required to enable wikidata to store the sort of data we want to store - such as academic papers with very many authors. As the building block of wikidata is the triple, it's disconcerting that the system design, according to Smalyshev's description, agglomorates these to sizes of 2M which it then finds indigestable. --Tagishsimon (talk) 21:48, 13 November 2019 (UTC)
I have stopped my batchs for now. On one hand, I understand that these big elements needs a lot of ressources, but on the other hand, I think it will be very sad to loose all these informations on them. Do the choices given by Pintoch are the only ones ? There must be another options. Simon Villeneuve (talk) 20:18, 13 November 2019 (UTC)
@ChristianKl: To test @Pintoch:'s theory, I would like to stop a number of QS batches which make edits to scientific article items (@Hogü-456, Daniel Mietchen: as the submitters of the affected batches; also @Charles Matthews: as someone whose batches, sharing similarities to those of the other two users, I certainly cannot stop due to their being browser-based). I am aware that this would cause quite the hindrance to a lot of workflows, but in the absence of closure regarding the prolonged Query Service problems I contend that at least trying to identify the source of the problem is paramount. Mahir256 (talk) 21:55, 13 November 2019 (UTC)
However from the WDQS graph on grafana it looks like the delay on the servers that used to be up to date has gone up over the past few hours so that they are ALL about an hour or more out of date? Are we missing something that's going on here? ArthurPSmith (talk) 21:07, 13 November 2019 (UTC)
fwiw, @Hogü-456, Daniel Mietchen: not getting with the 'maybe pause QS jobs' programme. And, fwiw, still crickets from service providers WMF/WMDE, as if there's not a problem severe enough here to disrupt all of our workflows; that's very poor indeed. WDQS1004 lag now 14.5 hours & rising. [11] --Tagishsimon (talk) 08:46, 14 November 2019 (UTC)
Guillaume Lederrey from the Search team has this morning posted this to the Wikidata mailing list [12], and a master-ticket phab:T238229 has now been created on Phabricator and given 'high' priority, so the Search team are aware of this and investigating.
One of the very striking things from the dashboard plot [13] is the significant difference between different servers - the groupings apparently corresponding to those in Virginia and those in Texas. Jheald (talk) 11:32, 14 November 2019 (UTC)
The write load (i.e. updates after item editing) is very similar on all servers in both data centers. However, they are routing most of the queries (read load) to the Virginia servers (AFAIR usually around 90% or so? Not exactly sure!). I don't know why it is done like that, though. It is also not clear to me why wdqs1004 and wdqs1005 are often more lagged than wdqs1006 which also resides in the Virginia data center. —MisterSynergy (talk) 11:47, 14 November 2019 (UTC)
Sounds like it's not even a query server issue, but rather a network problem. I wish I could select the server to respond to queries .. --- Jura11:57, 14 November 2019 (UTC)
No, I would not claim that. Simply spoken, the overall load (read+write) is simply too high. Options now are, roughly:
more servers or more powerful servers (does not scale well)
more efficient read software (i.e. replacing Blazegraph with something else; not available short term and not clear whether anything else performs better)
more efficient write software (this is what they are trying currently per phab:T212826)
limit read capacities (e.g. a shorter query timeout)
or limit write capacities (e.g. by adding WDQS lag to the maxlag parameter, which is also planned per phab:T221774)
I am not sure what the purpose of the Texas data center WDQS servers is, but if I assume that they are intended as a backup for the Virginia data center servers, one probably does not want to just use them with full load. "Backup" means that they are more or less idling, but capable of doing all the work if something goes wrong in the other facility.
Interesting read indeed. It seems to me that things are much better since the slowest server was taken out. (maybe it was just me that mostly got the slowest server). --- Jura13:17, 14 November 2019 (UTC)
I don't know if this is the good place to propose these 2 ideas. If not, please tell me where I should propose them. 1- For the items with > 2 000 authors, a lot of them are products of an association, like The ATLAS Collaboration (Q57661991) ([14]). Maybe we can create an item about the association, put it as author (P50) on the concerned items and remove all the authors of these items to put them only in the dedicated item of the association, with qualifiers as start time (P580) and end time (P582) for each author to know at witch article they have "collaborated". 2- Personnaly, I'm often frustrated by the WDQS timeout (and I strongly disagree with the option to reduce the computing time of it). I understand that we can't allow too much time to it and it force users to optimize their queries. But if the number of results is over about 100 000, or if it exceed about 3 millions in COUNT mode, it always timeout. For many queries, I (and I'm sure I'm not alone) don't need real time results. So I think that giving a query service as https://wikidata.demo.openlinksw.com/sparql , but running on the last dump, can help to unload WDQS, maybe by switching automatically on it when the queries are too heavy, giving an warning to the users that the results have been extracted from the last dump instead of the (real time|little lagged) data. Simon Villeneuve (talk) 14:59, 14 November 2019 (UTC)
@Jura1: et all is useless if you want to be able to research questions like "what papers has this person contributed to"; or "how often have these people published together"; or "which institutions did people come from, who published in these papers". Part of the value of the citation database we are building is that it can answer questions like that, and any other ad hoc queries that may occur to people. Jheald (talk) 15:31, 14 November 2019 (UTC)
For a question liek how often did to people published together, usually the intention will be to know how often they worked together. Sharing authorship on a 3000 person paper might not even include having talked to each other during the whole project. ChristianKl ❪✉❫ 19:09, 14 November 2019 (UTC)
This is a pretty big open question in the field of studying authorship & collaborations, and I agree it's not an ideal situation, but I don't think the answer is to create our own model for handling it. In general, the agreed approach among citation/bibliographic databases is to list all names given as authors, with collaborations only being listed where they're explicitly stated as pseudo-authors. We should respect that if we're aiming to replicate the functionality of these databases. Andrew Gray (talk) 20:08, 14 November 2019 (UTC)
Is it possible to get an notification if the lag of one of the query servie servers is higher than maybe two hours. So that the people know that they should slow down and how is the regulation of that for tools. I thought that when I use Quickstatements and run these batches in background that then the tool slows down or stops the batch if there is a lot of load at the servers. I havent read the first comment from Mahir yesterday and I dont look every time before I upload batches into QuickStatements in Grafana how high the lag is. Does the stop function in QuickStatements work. I think it must be possible to stop batches. I suggest to inform people who use Tools for big uploads like QuickStatements about lags and find a solution for stopping running batches in QuickStatements. -- Hogü-456 (talk) 18:37, 14 November 2019 (UTC)
The problem here is indicated at phab:T221774, which seems to have run out of poop in September after being opened in April. On the face of it, if we need to ration updates, bot owners honouring maxlag and maxlag taking account of WDQS lag, would seem to be an important part of the solution. It's puzzling that this feedback loop has not been put in place. --Tagishsimon (talk) 18:49, 14 November 2019 (UTC)
I can see that wdqs replication lag is <2min for last 6 hours. I was not aware of that discussion and neither stoped nor limited my edit rate (except for maxlag=5 of cause). Do you want me to stops now or we can consider that incident is resolved? Ghuron (talk) 06:44, 15 November 2019 (UTC)
I have restarted the bot, running only one batch (previously 2 in parallel for PMID 1-1999999, 3 for 2000000-4999999, 4 for 5000000-8999999, 5 for 9000000-13999999). I am still planning to increase the number of parallel batches if Query Service is healthy. The edit speed is currently 12-24 edits/min.--GZWDer (talk) 18:05, 16 November 2019 (UTC)
@GZWDer, Ghuron: Query server is not healthy. We're currently at 36 mins lag & climbing. [15] You are the major new item creators right now. [16]. Give some thought to the lag situation from time to time, please. --Tagishsimon (talk) 17:23, 18 November 2019 (UTC)
@Lydia Pintscher (WMDE), GLederrey (WMF): So after my change, edit lag was climbing with ever increasing speed for 6-7 hours. Is there any other meaningful activity that we can participate in order to address the real root cause of the problem? Like investigate what exactly is happening during lag climbing? Or vote for phab:T212826? What is the process of letting dev/ops know that community is interested in specific issue? Ghuron (talk) 04:03, 19 November 2019 (UTC)
From my side at least it's heard loud and clear that this is a problem we need to fix asap. We just finished the patches to take the query service lag into account for the maxlag parameter. That will hopefully be deployed in the next hours. As for more fundamental changes in the backend I'll let Guillaume say more but my understanding is that they need to fill the position that is currently open to be able to do this. We're left in a bit of a shitty interim situation with Stas' position being vacant after he left but that'll hopefully be fixed soon. I'm sorry I don't have a magic solution :( --Lydia Pintscher (WMDE) (talk) 18:21, 19 November 2019 (UTC)
I am not expecting you to fire magic bullet :) Thanks for update and let's hope we will survive another 6-12 months on "maxlag" duct-tape before someone get up to speed there. Ghuron (talk) 12:35, 20 November 2019 (UTC)
To which Wikipedia article would want to apply Wikisource badges like proofread, not proofread, digital document? --- Jura08:43, 16 November 2019 (UTC)
@MisterSynergy: I don't see that you argue the case. Firstly, the Wikisources have been using featured articles (see alias of "featured texts"), so citing Kaldari's proposal—which didn't emanate from the WS community—may be a circular argument.
I am well aware of the proofreading badges, having been involved with them for ages. I am more asking about the requirement for separating them. Noting that on the behalf of enWS that I requested the coding change that created digital document (Q28064618) which was labelled as a Wikimedia (the latter) upon its creation by the developer, and I have just changed it to be the former, and so started my questioning.
Secondly, your rhetorical statement about would they be applied to Wikipedia is interesting, because at this stage they can. If they can be applied to all interwikis then maybe they should be as "wikimedia", however, if they are indeed to be applied at a sisterwiki level, and this property will be the identifying restriction, then I can see the value in the separation. Hence why my question. — billinghurstsDrewth00:42, 17 November 2019 (UTC)
I did not really argue the case, I primarily wanted to just provide background where this items comes from and whom to ask. Also mind that part of the previous answers is by Jura1, not by me. —MisterSynergy (talk) 08:31, 17 November 2019 (UTC)
@billinghurst: I created Wikisource badge (Q75042035) because Beleg Tâl wanted me to set text status for Wikisource works on Wikidata instead of on Wikisource (per Wikisource:Scriptorium#KaldariBot). In order for that to work correctly (to display the correct icon and set the correct category), we either need to have Wikisource-specific badges or we have to hard-code all of that into the header template (which kind of defeats the purpose of using Wikidata to manage it). This is exactly why I wanted to just set everything locally on Wikisource, so I didn't have to worry about all these cross-wiki headaches, but Beleg Tâl though this would work better. Kaldari (talk) 23:47, 18 November 2019 (UTC)
@Beleg Tâl: It's definitely possible, but if the badges are Wikisource-specific, it will make sure that incorrect badges aren't displayed and that non-existant categories aren't added. The entire point of structured data is that you can encode things very specifically and make programmatic use of that information. Frankly, I don't care how it's set up, but I thought this would be an improvement. Re-using an incorrect badge just because it already exists is confusing and prone to cause problems. Do you and billinghurst have some reason why you want to do it that way? Kaldari (talk) 14:43, 19 November 2019 (UTC)
I don't care whether Wikipedia and Wikisource use the same badge for featured content or not; I just observed that they currently do use the same badge and wanted to know why you thought it was necessary to introduce the extra complexity of additional sister-specific badges. In my mind, it makes most sense to use one single "featured" badge for every featured sitelink regardless of whether it is an article, text, portal, or whatever; but if a multiplicity of badges is necessary for functionality then so be it. Beleg Tâl (talk) 23:41, 19 November 2019 (UTC)
It seems to me that any badge attached to a Wikisource sitelink is essentially a Wikisource badge. If badges are made specific to sister wikis, it is necessary to introduce new functionality to Wikidata to prevent editors from adding a non-Wikisource badge to a Wikisource sitelink or a Wikisource badge to a non-Wikisource sitelink. If a header module on Wikisource is checking badges for featured and/or proofread status, then it can filter out any other irrelevant badges that may be attached to the sitelink before displaying the information. Beleg Tâl (talk) 23:49, 19 November 2019 (UTC)
It's true, non-applicable badges can certainly be filtered out on the Wikisource side so they don't display. However, this feels a bit odd to me, because I can't think of when we'd want to do that: it seems more likely that a Wikisource work badged with e.g. top-importance article (Q17580682) (Why is that plural anyway?) has been badged incorrectly. Maybe we should just display an indicator for any badges that an item has? The main problem with that is as @Kaldari points out, that categorization won't always work because topic's main category (P910) won't be applicable (which of course we can also filter out). Anyway, if we want to filter out non-applicable badges, we have to have some way of identifying the applicable ones, and Wikisource badge (Q75042035) was an obvious way! —SamWilson09:34, 20 November 2019 (UTC)
I actually agree with Beleg Tâl that the most sensible approach would probably be to just have a "featured" badge, but it seems like it would be hard to switch everything to that at this point. If we are doing specific featured content badges, I think we should be consistent at least (to minimize confusion) and have a badge specific to Wikisource works (which generally aren't "articles"). Kaldari (talk) 16:39, 20 November 2019 (UTC)
Merge with QuickStatements not creating redirects ?
I recently did some merges via QuickStatements, and was surprised (batch 1; batch 2), and was surprised to find that, while QS has transferred the statements, it hadn't created the redirects -- at least, not in some cases (still checking).
Same again this morning. Only 3 out of a set of 8 merges fully executed. Does anybody else ever get this? Server stress, bad connection, or something else? JhealdBatch (talk) 11:56, 19 November 2019 (UTC)
I've occasionally seen this in the past, but I've also recently done batches of hundreds of merges with no problems. I have no idea what the issue is. ArthurPSmith (talk) 14:51, 19 November 2019 (UTC)
@GZWDer: Thanks for digging that out; but I'm not 100% convinced that it is the same cause as in that ticket. If I read it correctly, in 2016 these merges would be left hanging whenever there was a difference in the two descriptions. But (if I read the ticket correctly) since that time Magnus has set a flag to ignore the descriptions and whether they conflict. Perhaps he never did, but that's what he seems to have claimed to have done. Jheald (talk) 22:28, 19 November 2019 (UTC)
To me it seems like it is still the same problem as described in the phabricator task. From a technical point of view, merging and creating a redirect are two steps. If the "ignore description"-flag is set, merging items with conflicting descriptions is possible but the superfluous description on the old item is kept. And that prevents the subsequent creation of a redirect. To solve the problem, the old item needs to be cleared but neither the development team nor Magnus have implemented that clearing step. --Pasleim (talk) 11:31, 20 November 2019 (UTC)
I think applies to part (P518) -> cenotaph (Q321053) should be a used as qualifier for place of burial (P119), indicating that the cenotaph is at a different place, while the remains are elsewhere ("tomb" is an alias for place of burial (P119), which states "There may be several places: e.g. re-burials, cenotaphs, parts of body buried separately"). I don't see a compelling need currently to have new property for cenotaph location, unless perhaps if the cenotaph itself is otherwise notable. -Animalparty (talk) 23:40, 19 November 2019 (UTC)
"applies to part" seems more suitable for separate heart burials, e.g. "applies to part"=heart. --- Jura06:19, 20 November 2019 (UTC)
Are there cases where it wouldn't be worth creating such an item? It seems to me that cenotaphs for a single person are quite unusual. Ghouston (talk) 07:59, 20 November 2019 (UTC)
What property has been used for the domicile of a company?
Would this be the same as tax_residency or the same as place_of_incorporation? I am always confused by the difference between the two, we need a textbook definition, they are designed to be opaque. I agree we need the new property. For instance Apple Inc. moved their tax residency to the Isle of Jersey, but I think they created a shell company that holds their patents and the operating system, to lower their tax burden. --RAN (talk) 18:56, 19 November 2019 (UTC)
Thanks! I will go ahead and propose a new property. I will invite anyone knowledgeable of the topic to complement the request. See you there! – Susanna Ånäs (Susannaanas) (talk) 09:50, 20 November 2019 (UTC) There are at least two problems spotted: The definition and the datatype. Datatype: My data will have municipalities (items), but the place of incorporation can include a full address. Solution: Have the address as a qualifier? Definition: "Place of incorporation" is given as an alias to location of formation (P740) which is of datatype item. As noted earlier, the domicile may be changed, and this property is no longer a valid choice for the new location. Tax residency is not mentioned on any property. It might require another property, but I am not expert enough to know. – Susanna Ånäs (Susannaanas) (talk) 09:50, 20 November 2019 (UTC)
For users running QuickStatements batches after 15:36 UTC today: due to some reason you may see many errors about your batch. You may need to reset the errors more than one time when edits are busy. See Topic:Vbgypuu9k0q1pvz5 for detail.--GZWDer (talk) 18:46, 20 November 2019 (UTC)
This has already been discussed multiple times. I think in general there are three concepts: a) a building, which is a structure that can potentially be used for multiple purposes over time b) an institution or facility housed in the building, or across a group of buildings, and which can change buildings over time c) an organisation that operates b): which won't always be dedicated solely to b), e.g., it may be a government body with multiple functions. The same principle also applies to the likes of hotels, schools and hospitals. It's unclear if there are shortcuts that can be used to logically store information about more than one of a), b) and c) in a single item. Ghouston (talk) 22:28, 20 November 2019 (UTC)
I suppose in many cases, we'd only need an item for b). The other two may not be sufficiently notable or interesting. But we need "institution" type items that are neither buildings nor organisations. Ghouston (talk) 23:04, 20 November 2019 (UTC)
Some of them are functionally about the same, eg for Art Gallery of South Australia work ID (P6805) and quite a few others, one is \d+ and the other \d*. Others are subtly different, eg for Caverphone (P3880) the main format claim allows eight different letters, the constraint allows twelve; for Welsh Chapels ID (P4641), the format allows any length, but the constraint limits the number of digits; for Unifrance person ID (P3980), the two versions are the same except one is able to start with a "0" and the other isn't.
It feels like we should try and make sure they align if we're going to have both statements on the same property... or am I missing something obvious here? Andrew Gray (talk) 00:43, 19 November 2019 (UTC)
Now that property constraints are added as statements (the qualifier version), I'd delete all statements that are not constraints.
Some argument was made to keep them to give a more canonical definition of the format, but I'm not sure if that is understood or explains the differences you mention. They might just be statements that haven't been updated when the constraint was improved. --- Jura09:29, 19 November 2019 (UTC),
@Jura1, Pigsonthewing, Jmabel: thanks all - now thinking about whether we should switch all these to using constraint qualifiers only? It would need a bit of work to pick the "better" expression for each one, but probably the most recently edited one is more likely to be correct - as noted in the section below, a lot of these get updated in one place but not the other. I am not sure if there is anything that depends on properties having a format as a regular expression (P1793) instead of a constraint, though.
Some complications - there are 24 properties (this query has ~100 items as well, wasn't sure how to filter to just properties) which have a format but no constraint; would it be appropriate to create constraints for all of these, or do you think there's a reason they're not down as constraints? Andrew Gray (talk) 19:59, 19 November 2019 (UTC)
I'm new to WD. I welcome a cleanup of this to avoid confusion. Constraints is a very powerful and onshould be used whenever possible. I don't think we should care about external tools relying on this erroneously used property.--So9q (talk) 05:52, 21 November 2019 (UTC)
Changing a regex constraint - explain my fail, pls
The changes were made a month ago. However the constraint applied (e.g. at https://www.wikidata.org/wiki/Q1955420#P709 ) is the version prior to my edits, and the P709 talk page has, beneath the blue Documentation box, a format constraint infobox (?) also based on the prior version.
Hi, I just did my first merge. Is it correct? I became unsure because I don't know how the sitelinks work exactly. I merged because the two concepts were completely the same IMO.--So9q (talk) 08:47, 20 November 2019 (UTC)
I very much welcome a tool that via OAuth automatically ask for permission on the relevant changesets to the concerning users when doing a certain import. I imagine that 95% of users would agree as Wikimedia/Wikidata has good standing in OSM.--So9q (talk) 14:19, 21 November 2019 (UTC)
A few users stood out as often reoccurring in the dataset and I wrote them manually. (I found them via JOSMs - history dialog)
Hi!
At the moment Wikidata is missing every single hospital i Tchad.
I write to ask for your permission to import the coordinates and (if available) name on any hospitals you created or changed in Tchad?
Your permission is needed because Wikidata has CC0 as license.
Cheers
There is presently a problem with the HDS ID (P902): a link with only the last digits (those different from 0) doesn’t work anymore. Which means almost never (putting the adequate number of 0 at the beginning forces the link to work out, but with an error message). See for instance Paul Chaudet (Q118284). Would someone know how to fix this?Sapphorain (talk) 20:39, 21 November 2019 (UTC)
The same problem arose about one year ago (when the new version of the HDS was published, with one ore several leading zeroes added on many of the identifying numbers). The problem was then somehow solved. Sapphorain (talk) 21:17, 21 November 2019 (UTC)
The "Graph" results display should probably be called "network", which is the more commons parlance for an edges-and-nodes visualisation. This is especially the case as one of the other display options is "Graph builder".
Additionally, there are two features for the network display that may be easy to implement, but very valuable:
When two nodes point to each other, make single two-headed arrow rather than two single-headed arrows (example query)
Allow edges to be coloured by the type of property relationship that they represent, just like nodes can be (example query)
The default maps representation on the query service struggles when multiple results are spatially close or fully overlap (example query). Implementing an interface more like http://graves.wiki/ (GitHub source by User:Yarl) would massively improve usability!
Hello. Why is this language named Crimean Turkish on Wikidata?
"Crimean Turkish" is not used at all
And it's widely known that the first name of this language is Crimean Tatar, not Turkish
See these links:
@Devlet Geray: please restore the statement and alt labels you just deleted on Q33357. Wikidata attempts to include all variants. Do not attempt to suppress the ones that don't fit your POV. --- Jura12:20, 10 November 2019 (UTC)
Somebody who experienced in opening tickets should propose to fix the tooltip that's now showing Crimean Turkish. There are around 1500 ethnic Turkish people living in Crimea, and historically Crimea belonged to Turkey/the Ottoman Empire, so it may sound like Crimean Tatar is a kind of Turkish dialect. Even if this term is in use by somebody (in several English- and Turkish-speaking sources), it doesn't stop being simply incorrect. --Wolverène (talk) 11:01, 11 November 2019 (UTC)
It's not "simply incorrect", IANA does list both as valid names for the language but it lists Tatar first and there's no good reason to prefer Crimean Turkish over Tatar, so I agree that a ticket would be good. ChristianKl ❪✉❫ 13:24, 11 November 2019 (UTC)
As usual, requests are made in the issue tracker: http://cldr.unicode.org/index/bug-reports . crh doesn't have a locale, so this would be a change to the English name in the "Locale Display Names" rather than an "autonym" change. Remember to cite sources for your claim and don't consider anything to be obvious or "widely known" (in Western languages, by the way, "Turkish" is about as ambiguous as "Indian", another word which was used across the centuries for widely different things).
Comment 1) sounds veeeeeery specific, 2) sounds okay though an incomplete list for the range of honorary awards, 3) sounds too generic unless used as a qualifer, though what would the property which with to qualify. — billinghurstsDrewth10:07, 14 November 2019 (UTC)
I also like 2), although it's the least popular of the 3 methods. The other two don't distinguish an honorary degree in science from laws or letters. E.g., SUNY seems to issue a lot of these, and their variants are Doctor of Fine Arts (D.F.A.), Doctor of Humane Letters (L.H.D.), Doctor of Laws (LL.D.), Doctor of Letters (Litt.D.), Doctor of Music (Mus.D.), and Doctor of Science (Sc.D.) [17]. It's not a big list. Ghouston (talk) 10:42, 14 November 2019 (UTC)
No, all these methods are currently used. Even when using option 2), there seem to be plenty of cases where the type of degree is unknown or not distinguished, so it would be used in conjunction with 3). Ghouston (talk) 03:06, 16 November 2019 (UTC)
Where should bug reports be reported? I have this one: A new Item where you create a new statement with diameter (P2386). You add a value and then you add a length. Then add a applies to part (P518) and give it an item. Next you add a reference with date of retrieval, source url and publishe. Then try to save all at once. It tells you that it has some problems with the unit of measurement. I was able to save the data anyway by removing the unit of measurement and after saving adding it back in. I don't think the reference is really necessary. I guess the problem is with the unit of measurement and the applies to property. Can somebody confirm? --D-Kuru (talk) 19:54, 21 November 2019 (UTC)
@Ghuron: Apologies that I missed your reply earlier. Would you be able to confirm why embedding a wikidata query in a page is a bad idea? I'd have thought that if we allow embedding for other websites then it'd be safe for embedding in a wikimedia page (especially a wikimedia page about wikimedia). Currently I have just used static images on meta:Wikimedian_in_residence with links to the relevant query graphs and tables, but it feels sub-optimal. T.Shafee(evo&evo) (talk) 06:11, 15 November 2019 (UTC)
My assumption is that we want to render wikimedia pages to work as fast as possible for any visitor regardless of browser/TTS/media(pdf?). Having iframes with content that can load as long as 60 seconds (or even fail if blazegraph has bad mood) doesn't look very good from that point of view. There are a few cases when it is important to embed to wikimedia page life wd-info, but this doesn't seems like a case for that map. Some textual description and link to query results would probably do the trick. What do you think? Ghuron (talk) 06:28, 15 November 2019 (UTC)
The Wikidata Query service is already overloaded with work currently and we blocked a bot to reduce load. If your webpage sends a query for every visit that sends further work to the overloaded service which is bad. We would need some way to cache the result. ChristianKl ❪✉❫ 11:04, 15 November 2019 (UTC)
I think it depends on the query. In general, it's a good idea.
There are 3 or more ways to do it: static (Listeria), dynamic (LUA) and semi-static (graph). The last one is currently broken.--- Jura11:14, 15 November 2019 (UTC)
The complaint on enwiki seems to be that the lists can't be updated by hand, and it's too hard to figure out how to update the data in Wikidata. I'd have thought that anyone capable of updating wiki syntax tables would be able to handle Wikidata, but apparently not.[18] There's also an issue that Listeria doesn't seem handle lists properly where the same entry appears more than once, such as a politician who goes in and out of office a few times. Ghouston (talk) 23:55, 16 November 2019 (UTC)
┌────────────────────────────────────────────────────────────────────────────────────────────────────┘
Would this be different if the query result is displayed as e.g. a map or graph? T.Shafee(evo&evo) (talk) 02:23, 19 November 2019 (UTC)
has part(s) (P527) - is used to say that an instance has as part some other instance or that instances of a class have as part an instance of some other class
There should indeed be a "unique items for every external identifier", since those are describable concepts which meet our notability policy, both in and outside the 'structural need' clause. In the example given, the item is not "for the property", it is "for the identifier" Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits13:38, 23 November 2019 (UTC)
Problem with Q-items without any P31
Hi, I encountered a big annoying obstacle in the filtering for the lexeme tool MachtSinn.
The problem at hand is items like sort (Q7563757) (this by Sk!dbot) or flower (Q47034896) which have no P31 or any other meaningful way for me to exclude it via sparql. The only thing I can resort to is abitrary filtering by description and that is IMO not a good idea.
I hereby propose that either we curate all Q-items missing a P31 or we delete them. WDYT? Any takers?
From what I understand the only way I can get all of these (without specifying all the "subclass of" that they belong to manually is to sieve through everything in the database without a P31. Unfortunately such a query times out (because there are many, which takes us back to my proposition above). This is bad data quality.
Actually I do have the possibility of downloading the 41GB database myself, extract it (how much space is required?) and then sieve through it myself. If anyone have ever done this I would be happy to hear how it went.--So9q (talk) 17:33, 22 November 2019 (UTC)
No. Deletion is not going to happen. Neither is the problem going to go away. However you can easily exclude items with no P31, or no properties, from a SPARQL report. So there isn't a reporting problem here, I think. --Tagishsimon (talk) 17:35, 22 November 2019 (UTC)
filter not exists {?item wdt:P31 [].}
filter not exists {?item wikibase:statements "0"^^xsd:integer.}
Thanks, both of you! I'm glad I was wrong. Also I just found out that by adding a * after wdt:P279 I get all items in a subclass regardless if they have a P31 or not. Super nice!--So9q (talk) 17:52, 22 November 2019 (UTC)
A lot of items have been made with no links, only a "peer id". It follows that just because they are considered nobility they are notable EVEN when there are no statements and no discription. Given the huge numbers involved PLEASE STOP THIS NONSENSE. Thanks, GerardM (talk) 09:08, 22 November 2019 (UTC)
In my view these items probably are justifiable, as the same entity (even if currently only represented as "wife of 'X'" or "mother of 'Y'") is quite likely to have identifiers across a number of databases, that it would be useful to tie together.
As for the peerage import more widely, I think for a number of researchers this will extraordinarily valuable, allowing queries to be run on how closely inter-related large groups of notable people were, and what were those relationships. As well as stocking the House of Lords in the UK, important for national history, the peers were often the dominant landowners locally in particular parts of the country, of considerable relevance to local history, and to e.g. parsing local newspaper reports.
Most items are likely to have incoming and outgoing links of the family relationship type, so it is not true that these have been made with no links. As for external links, more of these, to more databases, are likely to be forthcoming, and the cross-referencing is useful. It is also likely that more relationships will become known as more sources are integrated, and the network will become denser. For the moment, I believe these items are useful, even just as placeholders to build more cross-referencing on. My view is that in this case it probably does make sense to import everything and then see what we've got, rather than prune the network too early. Jheald (talk) 10:27, 22 November 2019 (UTC)
With only a link to an external authority it is pure pollution, no items, no description. It does not link add or anything it makes disambiguation problematic. It extends the bias we have in representing the rest of the world. GerardM (talk) 11:02, 22 November 2019 (UTC)
Users are at leisure to contribute what they want. Obviously, it is biased if we tolerate descriptions for a Duke of Brittany (10th century) as "British peer or relation". --- Jura16:12, 22 November 2019 (UTC)
I am a bit iffy about importing ThePeerage en masse because they're not particularly careful about checking the data they grab up from various web sites -- sure, partly they're a digitization of Burke's, but they've gone far beyond that. As a way of quickly importing genealogical info it's a time-saver, but hopefully it should be treated just as a starting place for building proper, referenced entries! Levana Taylor (talk) 16:50, 22 November 2019 (UTC)
The mass import from The Peerage is the sole, unilateral effort of @GZWDer:, who appears not to have solicited any review, nor requests for bot permission beforehand, and who is being very vague and reticent about their ultimate plans. As the discussion immediately above this one points out, a lot of issues are arising. I think the mass import will ultimately prove constructive, but the lack of prior community discussion (that could have identified and addressed the issues now present like blank descriptions, ambiguous persons, no birth/death years) is disconcerting. -Animalparty (talk) 20:41, 22 November 2019 (UTC)
Many sources of The Peerage are primary (this make The Peerage itself a secondary source). The Peerage does contain various error, so it will be meaningful to compare Wikidata and other genealogical databases. I also do find errors in Wikidata data (some are imported from Wikipedia infoboxes which confuses people with same or similar names) using The Peerage data.--GZWDer (talk) 20:47, 22 November 2019 (UTC)
The issue is not whether The Peerage or Wikidata contains errors. The issue is that you undertook a huge project with apparently absolutely no prior warning or discussion, potentially adding a lot of extra work to clean up. And now people are concerned. -Animalparty (talk) 20:54, 22 November 2019 (UTC)
Regarding what I wrote above, I thought that at least these items would be being created with date of birth, date of death, and basic kinship information extracted from the website. Creating a blank record like Sir Merrik Burrell, 1st Baronet (Q75518248) when all this [19] is available from the website, that could be expressed in properties and statements, is very very poor. At the very least, a decent attempt to parse the most frequent forms of statement found on the website should have been made before any new records were created. (With QS it's much quicker to put the statements in at creation time, too). This needs to be fixed, very urgently.
It's especially painful seeing a duplicate record being made for a Member of Parliament, when User:Andrew Gray has put so much work into ensuring that an item and only one item on WD for each British MP.
Duplicate items are a menace, and can really screw up queries and automated matching. New items should not be created unless real real effort has been put in to try to avoid duplicates. Jheald (talk) 21:04, 22 November 2019 (UTC)
I share the concerns of Animalparty and Jheald. While I don't think advanced discussion was necessary before starting the project I do think that since many concerns have been identified, you should be willing to work with other editors to address them. Gamaliel (talk) 21:19, 22 November 2019 (UTC)
My main purpose of this import is to improve genealogical data in Wikidata (this will make Wikidata family tree 10-15 times bigger), so father, mother and child will be the first statements imported. Reinheitsgebot is currently importing date of birth, date of death from Mix'n'Match.--GZWDer (talk) 22:25, 22 November 2019 (UTC)
Thank you. Will duplicate entries (e.g. Sir Merrik Burrell, 1st Baronet (Q75518248) to Sir Merrik Burrell, 1st Baronet (Q7528324)) be identified and merged before or after the father/mother/child data is added? I think identifying and merging duplicates should come first, so as to avoid the creation of parallel family trees, and reduce potential errors when merging/redirecting merges. And merging sooner rather than later reduces the chance of bots importing dates that may be less precise (e.g. only year), or in conflict with dates already established. -Animalparty (talk) 23:05, 22 November 2019 (UTC)
I'm excited by the potential to see enhanced genealogical data! But will Reinheitsgebot be filling in this info for all the 398381 wikidata items with peerage links that are otherwise blank? And I share Animalparty's concern about the duplicates. Gamaliel (talk) 00:36, 23 November 2019 (UTC)
(Copied from WD:AN) I'm not convinced these items are even useful. "British peer or relation" is vague - is this person a peer, or a relation? As the discussion has demonstrated, we don't even know whether the person is British. In the example suggested by User:Jura1, Doreen Margaret Billington (Q75504158), all that there is on the item is that this person exists and you may look up their genealogy on a certain page at The Peerage. Or my friend Olivia who is arguably more notable as a research scientist, but your script created an orphan item for her that doesn't even link her to her aristocratic relations. If you're able to import the entire family tree into Wikidata as statements and eventually link them to someone with a baronetcy or a Wikipedia article then that might serve a "structural need" purpose for Wikidata, but as these item stands I doubt that they conform to Wikidata's inclusion criteria. I propose that we should mass delete all The Peerage items that have no sitelinks, no incoming links, and no other external identifier other than The Peerage. Deryck Chan (talk) 16:30, 23 November 2019 (UTC)
The import new items is currently 99% completed. Once the import are completed, statements about family relationship will be imported.
Many people are relatively unknown, e.g. Doreen Margaret Billington is only known as a sister-in-law of Victor Henry Peter Brougham, 4th Baron Brougham and Vaux (Q7925756), but in my opinion this relationship as described in the Burke's already make the item notable - as it can not be expressed without this item. Many people can also be found in other genealogical databases. Reinheitsgebot is starting matching items with genealogics.org.
For Olivia, I also added an ID from another site. The information apparently comes from a source similar to Burke's, as it does not list any real-life activity of Olivia, but only list this as someone's child. I also found any other information about (apparently to be) Olivia. I have create another item, as no (self-published included) non-genealogical source provided birth date and parent information about Olivia, and adding them without a source violates Wikidata:Living people (interestingly, Cooper-Hewitt person ID (P2011) requires people having a birth date). I don't know what's the proper way to handle this. I did remember a case that a Wikipedia had two articles (and thus two Wikidata items) for a person with two identities and does not (until recently, but whether the source is valid was debated) have a source to confirm them as one person.
Please explain to me why this is of historical interest. What does it teach us. Why is it of more relevance as geographic and data or a Wikipedia. Particularly as the point is made that it created oodles of duplicate data. Thanks, GerardM (talk) 12:51, 24 November 2019 (UTC)
So9q If you add statements that have no media reference but are inferred, then please give a reference using based on heuristic (P887). I see there is a qualifier determination method (P459)-->Q76109020, additionally I have added such a reference. Not sure if it's needed. The query URL is an idea but I think it would be better to put the query on a wiki page or a gist and refer to that. --SCIdude (talk) 14:51, 23 November 2019 (UTC)
"point in time" on the population is meant to be the day the region had such a population, not the day you ran the query or retrieved the data. --- Jura15:07, 23 November 2019 (UTC)
To compute a consolidated population, I think I'd pick a similar date (e.g. same year) and numbers that use a similar method of calculation (or reduce the overall precision).
There is presently a problem with the HDS ID (P902): an identifying number with less than 6 digits, with only the last nonzero digits doesn’t work anymore. Which means almost never (putting the adequate number of 0 at the beginning forces the link to work out, but with an error message). See for instance Paul Chaudet (Q118284). (The same problem arose about one year ago, when the new version of the HDS was published, with one ore several leading zeroes added on all identifying numbers with less than 6 digits. The problem was then somehow solved, a few weeks later). Would someone know how to fix this? The prospect of having to add zeros on each occurence of an identifying number with less than 6 digits appears rather appalling! Sapphorain (talk) 18:04, 22 November 2019 (UTC)
This is a praiseworthy devotion. But you should be aware that, even if you succeed in putting leading zeroes to all identifiers in all Swiss pages, only the tip of the iceberg will be mended: in most of these pages there are also a number of statements, sometimes more than ten, that have as a reference an entry (or several entries) of the HDS. For instance in Louis Odier (Q1871755) twelve statements are referenced by an identifier of the HDS...Sapphorain (talk) 08:30, 24 November 2019 (UTC)
As a simple(?) example of what I was writing about above, of modelling things that provide services such as museums but which are not necessarily buildings or organizations, I'm considering restaurants and similar entities. The relevant items are not very plausible, at the moment, it seems to me, since we have for example:
It seems like any place that serves food is a building and a business. I can think of a lot of exceptions without much trouble: restaurants that don't fill an entire building, and obviously aren't buildings. Restaurants that are part of a chain and aren't separate businesses. Canteens in hospitals or army bases that aren't commercial and are neither buildings nor businesses. Companies, from a legal and accounting point of view, are virtual entities consisting of things like owners, property owned, a balance sheet, officers, and contracts: they don't have presence in the physical world.
A hierarchy of items that is independent of the building and business ideas would look something like this:
Eating place: a space allocated for eating food
Dining room: a room allocated for eating food, subclass of eating place
Food distribution point: a place where ready-to-eat food can be obtained
Restaurant: an establishment where food can be purchased and consumed, subclass of food distribution point, eating place, and commercial service
Cafeteria: subclass of Restaurant
Cafe: subclass of Restaurant
Intitutional canteen: subclass of food distribution point and eating place
Refectory: subclass of intitutional canteen (possibly an alias)
Mess hall: subclass of Intitutional canteen
Takeaway outlet: subclass of food distribution point and commercial service
I think the general problem here is ambiguity of meaning in our items, and different meanings supporting conflicting class relations up and down the hierarchy. It's definitely helpful to clean this up and be clearer. I think I follow your proposal, it's a reasonable start. What about "food courts"? Do we need a separate classification to describe whether or not food is actually prepared in some way at the establishment? ArthurPSmith (talk) 21:26, 23 November 2019 (UTC)
It looks like a food court (Q1192284) would just be a subclass of eating place. A place where food is prepared, I suppose in a generic sense is a kind of factory, or assembly / fabrication place and a kitchen is a subclass of such a place. But a restaurant could still operate even if all the food was shipped in prepared elsewhere: I guess there are cafes that operate like that and above I've got cafe as a subclass of restaurant. You could potentially have "restaurant with on-site food preparation" as a subclass of restaurant, but do we really want that level of detail and complexity? Ghouston (talk) 03:31, 24 November 2019 (UTC)
Although, given that drink (Q40050) is a subclass of food, the normal case that I'm familiar with is that a restaurant/cafe would have on-site food preparation, even if it's just mixing coffee. If there's a class of exceptions then that could be a separate item. Ghouston (talk) 21:38, 24 November 2019 (UTC)
Please speed up! I requested several months ago. Addition by hand will always leave errors even if someone agrees to do the work. --RAN (talk) 03:18, 25 November 2019 (UTC)
Google Knowledge Graph ID
Is their an automated way to add these. I use the Google API which is tedious to log in and search. Is there some secret to getting the ID from the box on the Google search page? --RAN (talk) 03:20, 25 November 2019 (UTC)
This change will be operated this week, on November 20th. If you're editing Wikidata using keyboard shortcuts, you will still be able to jump from a field to another using the Tab key.
Update: the change will be deployed on December 5th (no train last week and this week).
@So9q: I don't think there is a shortcut for the action of adding a statement, but maybe someone else knows a trick? As for the tab, we usually don't change the core interface of the wiki, unless there is a strong need or a request by a big number of editors. However, you can edit your CSS or create a gadget to make the link more visible for you. Lea Lacroix (WMDE) (talk) 10:46, 25 November 2019 (UTC)
2 import policy proposals
Hi, I hereby propose that we:
decide not to allow any import of any item without a P31. The reason is that any query that I try in SPARQL to filter out any items fail and that makes it really hard to discern the over 3 million items currently without P31 or P279.
make a new policy to make it mandatory to discuss new imports first with the community on a designated place (if no such policy exist). WDYT?--So9q (talk) 22:29, 23 November 2019 (UTC)
Even if items with only sitelinks and no other statements have various benefits (easier detection of duplicates; make various tools works).
From time to time there's new data imported to Wikidata. I don't think it's possible to discuss each import before import (many import are not controversial and users ultimately are reasonable for their imports).--GZWDer (talk) 22:35, 23 November 2019 (UTC)
(edit conflict)
I disagree. In OSM there is a mailing list where all imports need to be discussed. You get feedback by seasoned mappers on you import plan (mandatory to create in the wiki) and can then go ahead if the (local) community agree to accept the data. I have only been active on WD for a short period but the there I have found a lot of bogus imports with missing statements. 2 examples: heritage sites by AliciaFagervingWMSE-bot, Hebrew calendar years by GZWDer, etc.
WD seems like wild wild west to me so far and examples like these unfortunately contribute to bad data quality which down the line shows up like bogus matches in a tool like MachtSinn that I recently tried to filter false positives from.
We need to focus on data quality and curation more than low quality mass imports that polute the whole and make it hard to search/use the data utilizing intelligent queries.
My stance is this: if you can't come up with a good import plan the data is best not imported by you. A good import plan includes relevant statements and as a minimum a P31 statement describing what the Q-item is a an instance of. The more relevant statements per entry the better queries we can make.
One more proposal to make mandatory: imports have to add a statement to the item they create that links to the import plan. This ensures that if someone come down the line and realise a statement was missing in the original import we can EASILY discern the import and curate all the items. This is mandatory in OSM to easily find what imports touched what data.--So9q (talk) 23:06, 23 November 2019 (UTC)
We did discuss the bulk creation of items for sitelinks without P31/P279 extensively. The conclusion was that I was the only one who didn't like it ;)--- Jura22:43, 23 November 2019 (UTC)
I hereby propose that relative newbies with few edits, limited SPARQL skills, and a limited understanding of wikidata, should not propose "import policy proposals" until they have a clue. Neither of these is going to happen. --Tagishsimon (talk) 22:55, 23 November 2019 (UTC)
Thanks for your comment. I note that you did not present any argument for why we should continue to accept these wild west environment and the detrimental effects to our data quality that I gave examples of above.
It is a fact that our SPARQL system is not good at handling millions of entries in a diverse subtree which makes filtering within the time limit of queries harder than necessary. (see argument by Andrew in the discussion Lets decide about limits for sizes of human settlements above).
This also makes it almost impossible (for me) to curate items that don't have a single P31 or P279 statement. Additionally a P279 alone is not always enough because queries that traverse large taxonomies time out easily as I'm sure you know.
Q-items that cannot be reached easily by a query could might as well not exist IMO. They are not that valuable because they lack what is needed to effectively curate them and thus is very susceptible to data rot and creating headaches for data consumers (e.g. the MachtSinn tool).--So9q (talk) 23:18, 23 November 2019 (UTC)
Your last sentence is a good illustration of why your proposal is problematic, you don't seem to understand that there are plenty of usages of Wikidata that have nothing to do with queries. Providing interwiki links would be one of those functions that work even without P31 or P279 and it's important to make this provision of sidelinks as smooth as possible for Wikipedia users who might not know what P31 or P279 is about. I agree with Tagishsimon don't think a detailed discussion of this proposal is a worthwhile energy investment. ChristianKl ❪✉❫ 23:46, 23 November 2019 (UTC)
@Tagishsimon .. it's "the free knowledge base with 68,510,987 data items that anyone can edit.". So anyone can make policy proposals .. even if they are incompatible with that. --- Jura23:21, 23 November 2019 (UTC)
For time being, I'm struggling to improve data quality, and I happen to find some items to merge with. Improving P31 population would definitely help and if newbies could be more patrolled, (ie they could import freely but could get a cancellation by administrator if no P31, etc with a page of "do"-"don't"s. If you feel like to enter the battle of data quality, just use any like of this queries. Bouzinac (talk) 20:44, 25 November 2019 (UTC)
(P1648)
Why does this statement bring up an error "single value constraint (This property should only contain a single value.) When the actual site is a duplex one with the same articles in Welsh and English? Why is there a constraint that should match the regex s\d{0,2}-[A-Z0]{4}-[A-Z0]{3,4}-\d{4}, when a link to the Welsh version should be equally valid? Is Wikidata an English only source? AlwynapHuw (talk) 04:10, 25 November 2019 (UTC)
Would it be possible to format the constraint to have precisely two values, and distinguish each one by a qualifier statement? The alternative would be to implement the original suggestion of stripping the initial 's' or 'c'.
The owner of Lingua Libre Bot is not responding to comments left on his talk page. The bot continues making edits that other editors have questions. --EncycloPetey (talk) 01:08, 26 November 2019 (UTC)
Copy to clipboard action in search results
When using Mix n Match, when a Wikidata search is triggered it shows results and often the right item can be seen in the results. Might it be possible to add an extension that provides a "Copy to Clipboard" icon next to the Q-number that would copy it to clipboard? Pauljmackay (talk) 20:05, 25 November 2019 (UTC)
'copy link' and you can paste the link into input fields and get the item. I can see the need for the Q-part only, however. --SCIdude (talk) 16:08, 26 November 2019 (UTC)
song mentioned in wikipedia article without its own wikidata item and games with vast collections of 'since long' published music
On the English Wikipedia page for Maze (Q446422) it is mentioned that the song "Twilight" appeared in the video game Grand Theft Auto: San Andreas (Q83265). Is the article about the band Maze in which this song is mentioned enough to create a wikidata item for it? If not is it relevant in the regard of making the wikidata item for the video game Grand Theft Auto: San Andreas (Q83265) more complete?(the gta series contain vast amounts of music that has already been published separately, should the individual music pieces be included in the video game wikidata item is kinda my question) Wdtaplaylistcenter (talk) 10:43, 26 November 2019 (UTC)
Join the global m:WikiForHumanRights Campaign by participating with WikiProject Human rights. The campaigns is focused on increasing coverage of human rights topics on Wikimedia projects through January 30.
Cradle enables editors to create a new item by completing a form. You can create a new form on the Cradle help page. Cradle forms can be used as templates to ensure that similar new items are structured the same way. This can be especially helpful for specific WikiProjects or datathons, and is a great timesaver if you are creating many similar items by hand.
Other Noteworthy Stuff
570k VIAF identifiers have been added to Wikidata items in an effort of synchronisation between the two databases, thanks to Bargioni. In order to report errors in VIAF an apposite page has been created. More information here.
Query Service lag now affects maxlag. You may need to retry/reset error multiple times when you run QuickStatement or OpenRefine in busy hours.
Wikidata now documented more than six million people, more than the number of articles in English Wikipedia
I will filter by descriptions then and leave those I cannot discern without a P31. I understood these answers as a go ahead you don't need a bot account for this.
I updated the description of heritage site (Q358) to: general term for a site of cultural heritage for a specific country (please avoid as a P31 valuable except for large sites containing multiple entities)--So9q (talk) 23:25, 23 November 2019 (UTC)
@So9q: It's a good idea to have a separate batch account with a bot flag for batch editing. Apart from anything else, it makes rollback easier if anything goes wrong. Jheald (talk) 15:27, 26 November 2019 (UTC)
Ok, I'm considering applying for one for another project idea. I ended up only updating a few hundred via QS2. The rest had almost no labels (aside from a few houses and castles). Pictures were there though so somebody could create a game to work through them classifying them further.--So9q (talk) 19:43, 26 November 2019 (UTC)
Hebrew calendar years - inconsistence found
Hi, I found inconsistently tagged hebrew calendar years:
I agree that 3) is preferred because a year is not really a "part of" a calendar system. It is also easiest to query IMO. Big thanks for the PetScan tip. :)--So9q (talk) 19:06, 24 November 2019 (UTC)
I tried finding a category on the hebrew wikipedia but failed. I leave this for somebody with knowledge of hebrew to clean up.--So9q (talk) 19:46, 26 November 2019 (UTC)
I would like to add to the claim that I am not fully convinced that this is a correct interpretation of the source. How do I add such doubt to a statement? 62 etc (talk) 06:01, 26 November 2019 (UTC)
Well, the main problem is rather that I do not know enough about central european folklore to judge if the person I have linked is the right Ottilia. 62 etc (talk) 19:31, 26 November 2019 (UTC)
B-side_(DEPRECATED)_(P1432) empty and ready for deletion
While browsing around with Wikishootme, I stumbled upon the two items Q26713622 and Q26713630, which are about the graves of two notable persons. However, these graves by itself don't seem notable (not heritage monuments) nor have any Wikipedia article linked, so I really wonder if we should keep them as separate items, as all the information can be recorded at the item for the person buried there. Ahoerstemeier (talk) 10:20, 20 November 2019 (UTC)
Under our structural need provision of the notability policy, the fact that the items help to describe the other notable item makes them notable as well. Structured data works better when information about different entities is moved to different items. ChristianKl ❪✉❫ 11:19, 20 November 2019 (UTC)
@ChristianKl: What structural need does this item fulfill? What link between the person item and any other item, wikipage, or external site would be lost by removing it? Jheald (talk) 12:49, 20 November 2019 (UTC)
I could imagine that if two or more (notable) people were buried in the same grave, it would be better to link them to the same grave item rather than to duplicate the coordinate location (P625) data on each person’s profile, but I agree that for non-notable graves of a single notable person it’s better to keep the data on the person’s profile. Dogfennydd (talk) 19:02, 20 November 2019 (UTC)
I didn't look at the items in question. If all the information is really already on the original item then I agree that there's no structural need. ChristianKl ❪✉❫ 22:31, 23 November 2019 (UTC)
As someone who works a lot on graves and graveyards, I see no need for a separate entry on a grave unless it appears independently in an authority file, for instance if VIAF has an entry for it. VIAF has been creating entries based on our entries so we may get some recursive problems. --RAN (talk) 01:28, 21 November 2019 (UTC)
In some cases Commons has plenty of pictures and a category. In these case, I think it might be worth creating items for these. Merely linking the category seems suboptimal. --- Jura01:50, 24 November 2019 (UTC)
I have added hundreds of pictures of gravestones, every gravestone for some small cemeteries, but I think it would be best to have the entry for the human and just use the "image of gravestone" field. There is room for the GPS coordinates of the stone with the image as a qualifier. We should always try and consolidate information into a single entry. For instance we could have an entry for every house as well as tombstone, or just use the "secondary image" field to show the house someone lived in. Of course if the house or tombstone has an entry in VIAF or other authority file, it should have its own entry here. So I think merge the two entries for Q26713622 and Q26713630. --RAN (talk) 17:00, 27 November 2019 (UTC)
Not able to delete non-Northern Saami garbage from aliases for Q2994857
The only correct form in Northern Saami for this organization is "Murmánskka Guovllu Sámesearvi", i.e. the current label. When I try to delete the incorrect languages out of the Northern Saami aliases, I can't and I don't know why. I would appreciate any and all help. -Yupik (talk) 00:19, 27 November 2019 (UTC)
There is a glitch where some people cannot delete entries that contain overflow text in the "also known as" field. It has been reported and a ticket is open for it. --RAN (talk) 15:34, 27 November 2019 (UTC)
Actually, if the list in the source website isn't meant to be a list of authors, it could be correct to include the institutions there. One more reason not to use P50 for lists of all physicists alive. --- Jura10:38, 25 November 2019 (UTC)
Is it only me or have other contributors experienced time-out when trying to use the Author Disambiguator tool the last couple of days? --Cavernia (talk) 11:46, 28 November 2019 (UTC)
There's a user, Celette, which is a shared account, made more than 1000 edits in Wikidata. Many of them are non-trivial. The edits themselves don't seem unconstructive. See also:
Currently Wikidata:Alternate accounts does not explicitly state whether shared/role account is acceptable. I propose to add one of theses to Wikidata:Alternate accounts (not include any small text) to clearly state the rule of shared/role accounts in Wikidata:
Any user account may only be used by one individual. Any accounts shared by multiple people or representing an organization may be blocked indefinitely. The only exceptions are non-editing accounts approved to provide email access or bots operated by multiple users; in both cases the use and theactual operators of the account must be publicly declared in user page. This is similar to the rule in English Wikipedia.
Accounts representing a organization, non-editing accounts approved to provide email access and bots operated by multiple users are acceptable, provided that the use and the actual operators (either real name or Wikimedia user name) of the account is publicly declared in user page. Other kinds of shared uses of account is prohibited. This is similar to the practice in Wikimedia Commons. Note that as Structured Data is available, many users editing Structured Data may needs to edit Wikidata.
An account may be operated by more than one individuals. The real names or Wikimedia user names of operators must be publicly declared in user page. This is the most lenient policy, though still comply with the current alternate accounts policy. Some Wikipedias do not prohibit shared account, this will make them able to edit Wikidata now.
Without even giving the issue any thought - I can immediately say that am against anything that requires me to post my name publicly. Especially in this situation where I would be associated with Company X. A private sign up, where only the foundation/admins/etc sees that I work for Company X, would make it easier to accept. But I can't have my identity available publicly for all to see (and repost at will) just because I wanted to make $7 an hour over the holidays to buy my kids some Christmas gifts. Quakewoody (talk)
Users then are encouraged to create an additional personal account if they are currently using a shared account if they don't want to disclose their name.--GZWDer (talk) 15:42, 26 November 2019 (UTC)
nope, I am not going to be sold on it. Using the above scenario, where I took a part time job over the holidays for some extra cash. I would be required to use the company account. But my name shouldn't be required to be publicly displayed. I know people who have had their names publicly posted, and I know the hassle it brings. I cannot stand behind anything that puts someone in that situation. Making a private disclosures is one thing, that way it is on record, but not something accessible to you and me and anyone with access to the internet. Quakewoody (talk)
I think the most telling point here is that some Wikipedias do not prohibit shared account. Given our special central role in the WMF community, we should be very cautious about imposing restrictions more stringent than those of some client projects. Bovlb (talk) 16:02, 26 November 2019 (UTC)
Shared accounts don't seem any more harmful than accounts run by one individual. Indeed the question of how many people use an account borders on the bizarre. Treat it as an account. If the account does bad things, warn and block, &c. The idea that users of the account need to identify themselves is for the birds - or to put it another way, deeply repugnant pointless damaging control freakery which does nothing at all to alleviate any supposed (but hitherto unarticluated) problem. --Tagishsimon (talk) 16:24, 26 November 2019 (UTC)
I don't think it is an issue at all. In pl.wiki we have even an account with admin privileges that is used by two individuals. More problematic are multiple accounts run by one individual, but we shouldn't do anything about it until those accounts are harmful in some way. None of the propositions is acceptable for me and what's probably the most important thing here: there is no way we can tell that an account is used by more than one person. Wostr (talk) 16:46, 26 November 2019 (UTC)
In the past we usually agreed that we want to allow account names that suggest that an organisation is behind the account. From my perspective it's useful to have such accounts to allow organizations to interact with Wikidata. Instead of requiring disclosure of names I would declare such account to be inegible to vote. ChristianKl ❪✉❫ 16:52, 26 November 2019 (UTC)
@Bovlb: Please note the sock policy here is already very strict within WMF wikis. Many wikis allow alternative accounts for privacy purposes and clean start without disclosure; enwiki even does not require (strongly recommend only) alternative or former accounts to be disclosed while requesting adminship. Here we require disclosure all alternative accounts of all purposes.--GZWDer (talk) 19:48, 26 November 2019 (UTC)
@GZWDer: Thanks. All good points, but I stand behind my position that caution is required here. Suppose someone uses an alternative account to rename a page on some Wikipedia, and that automatically causes an edit here on Wikidata. How does this policy apply if the account is proper on the home Wikipedia but improper here? If someone follows "edit data in Wikidata" link from a Wikipedia, how are they to know that their very account is suddenly improper?
Chemical compounds are used as drugs, food additives, solvent and many more, also have functions as inhibitors, antagonists etc. It seems that there is full freedom in using one of the following properties:
subject has role (P2868) is created to be a qualifier to make an existing statement more specific. We lack a few properties to describe chemical components well. Ideally, someone would think about what properties we need and then make proposals. ChristianKl ❪✉❫ 10:30, 27 November 2019 (UTC)
Since 1. no one has an argument against this being used as a main property, and 2. there is no property that can be used e.g. for parts of chemical processes where no person uses the item but the item has a role nevertheless, and 3. because the creation with a constraint created tens of thousands of useless conflicts I will remove the constraint tomorrow at the latest. --SCIdude (talk) 14:35, 27 November 2019 (UTC)
I only remembered our reinterpretation and not the initial proposal. I agree that it's sensible not to remove the initial usage pattern. If we decide for that, we however should change the description. ChristianKl ❪✉❫ 12:26, 28 November 2019 (UTC)
I agree. One of the main reasons it currently isn't is that we often have multiple items for one FMA identifier. One for the human version of the anatomical feature and one for the version that's not species bound. ChristianKl ❪✉❫ 14:13, 26 November 2019 (UTC)
When the licence is CC0 is there anyway to track when the data from Wikidata is used for commercial purposes? The fact that when the CC0 licence permits the use of data of Wikidata anywhere and for any purpose is understandable, but the contributors must be given the confidence about the flow of data. There are no clear protocols on the levels of sensitivity of the data that is published here, this will refrain users from trusting the platform.
Please let me know if my understanding is wrong at any point or I am also ready to help in standardising the project as I find it useful and helpful for various reasons and as lover of Open Knowledge movements.
There's no way to track all ways data is used. If you don't want data to be widely used then you shouldn't upload it to Wikidata. As far as sensitivity of data goes we have Wikidata:BLP that limits some private data. ChristianKl ❪✉❫ 12:39, 29 November 2019 (UTC)
If you go to the bottom of Wikidata:Property_proposal/Authority_control, you'll notice the last 5 proposals are not transcluded but only given as links (whereas 72 proposals are transcluded), and at the bottom "Categories: Pages where template include size is exceeded".
@Mahir256: I never archive proposals myself, that is done by DeltaBot periodically (but I guess it can probably done manually in situations like this). Thanks to DannyS712 who closed quite a few long-standing proposals, this should soon become more manageable. − Pintoch (talk) 17:04, 28 November 2019 (UTC)
DeltaBot normally waits with archiving a couple of days after a proposal gets closed (the poposal might get reopened...). I've now speeded up the process now. --Pasleim (talk) 17:54, 28 November 2019 (UTC)
Hi Logan. You've made 39 edits to wikidata. There have been 1,060,623,795 edits since Wikidata was started, and edits are running at - I forget - somewhere north of 500,000 per day. We're grateful for any good work you do, but keep a sense of proportion. --Tagishsimon (talk) 23:55, 24 November 2019 (UTC)
@LoganTheWatermelon: In the link you give, you want to talk about Canimals (Q3655358). Be aware that sitelinks do not have the same POV. I have reverted several times your clumsiness, but you come back with your bad translation. For starters, POV-pushing is not the right strategy. —Eihel (talk) 22:19, 29 November 2019 (UTC)
@LoganTheWatermelon: You wanted some more attention. Here it is. If you edit war, as you are doing at Canimals (Q3655358) and if you call other users liars (diff) you will very quickly be blocked. Life is too short for that sort of bullshit. Either walk away from the issue, or start discussing in a civil fashion. Only warning. --Tagishsimon (talk) 22:35, 29 November 2019 (UTC)
Is there a way to tag Requests for Deletion to be archived?
At the moment there are a lot of items in Requests for Deletion and in some cases the items were improved to the extend that it doesn't make sense to delete them anymore. I see no document process of how to handle those items. What's the best practice? Should we write it down in the header of Requests for Deletion? ChristianKl ❪✉❫ 23:09, 29 November 2019 (UTC)
It looks as though you want to sort the values associated with a single property, rather than sorting a group of properties. You can use series ordinal (P1545) with values of 1, 2, 3, ... to indicate the sequence of items, if you have a complete list. --EncycloPetey (talk) 02:02, 30 November 2019 (UTC)
There isn't currently any way to order different claims in a property, or different qualifiers on a claim. It's been requested before but I think there simply aren't any technical mechanisms we could use for it as yet, or any firm idea how we should do the ordering (by preferred/normal/deprecated ranking? by a list of suggested values like with sorted-properties? by values on qualifiers like start time or series ordinal?). At the moment, it's essentially first-comes-first, so you could in theory re-order them by selective deletion and reuploading, but this would be an awful lot of work (and introduce the possibility of errors) for purely cosmetic benefit. Andrew Gray (talk) 11:50, 30 November 2019 (UTC)
I think there's a sequence number so the properties remain in the same order over time. You could probably change them through the API, by replacing the entire statement. Ghouston (talk) 01:37, 1 December 2019 (UTC)
I recently explored about Wikidata and how the background works and got a few queries on the project per se:
Why Blazegraph when other smooth GraphDB with even more decent features available in Open Source world? I know that it would just take little more efforts to migrate from the SPARQL to GraphQL, but since both have the base on SQL it should be easier to move on.
Blazegraph was reasonable choice few years ago, but it is clear that project is dying (see [21]). It will not stop working overnight, but we should actively look for replacement in the next 12-18 months. Feel free to suggest "other smooth graphdb" here as long as they fulfill defined requirements.
I don't want to start SPARQL vs GraphQL debates here, both have their strengths and weaknesses. But SPARQL was here for several years and there are hundreds (if not thousands) clients that relies on SPARQL to access wikidata. I do not see how we can migrate all of them to GraphQL with "little more effort". But nevertheless I do believe that there are room for both SPARQL and GraphQL wikidata endpoints. The only question is who will do this "little more effort" :)
Neither SPARQL nor GraphQL "have the base on SQL". SPARQL design is heavily influenced by SQL but some pieces of SPARQL cannot be expressed in SQL (see second bullet in mw:MW2SPARQL#Known issues). GraphQL can sit on top of SQL database, but it is not a requirement. Ghuron (talk) 11:33, 1 December 2019 (UTC)
Is the plan to eventually have "depicts" at Wikimedia Commons show up here when I click on "What links here"? That would be very useful, twice someone deleted an incomplete entry I created here not knowing it had and active link from Commons. --RAN (talk) 18:26, 25 November 2019 (UTC)
Some of these peers have a name that includes a military rank. First, they were not born with such a rank, it is probably the end rank of a military career. We do not support the use of a rank in names and consequently they need to be removed.
Also, I take it that we accept these peers and as a consequence all the hassles associated with it. I expect that other domains may enjoy similar accomodatons.. Do you all think that is reasonable? Thanks, GerardM (talk) 13:02, 30 November 2019 (UTC)
There are about 100,000 items that need prefixes in labels removed.
Labels of the 500,000 items probably also need fixes in other ways: for non-British titles, some should likely not be in labels, but these are harder to find. --- Jura13:14, 30 November 2019 (UTC)
When we accept that so many labels are wrong and that we are to accept these labels, that we can accept similar error counts in other efforts? Thanks, GerardM (talk) 15:40, 30 November 2019 (UTC)
Do we? I can't really speak for you. In any case, cleanup has already start. 20% (or even 10%) is way too high. --- Jura16:35, 30 November 2019 (UTC)
Just to note that such labels should not be removed altogether, so much as moved to the alias. Beyond that, it's not an error so much as a thing that can be improved over time. "The label is the most common name that the item would be known by", per Help:Label, and although it is our custom to use a names shorn of titles in labels, including titles is far from wrong, especially where people are commonly known by those end rank of a military career titles. In the UK, I suspect more people known Field Marshall Montgomery than know he's called Bernard. And AFAIK Earl Haig's first name - Douglas - is still a state secret. To be clear, I'm all for improving the labels, but it needs a little more thought than making it into a crude stick with which to beat GZWDer. --Tagishsimon (talk) 16:27, 30 November 2019 (UTC)
I do not make it about anyone in particular. For me it is about how do we deal with issues like this. Are we evenhanded in this? We have acquired a more and more repressive mode of operandi.. When I started I could do and did tens of thousands of edits in an hour, now a process I ran used one hour and a half for a little over 200 edits. I find that more and more it is an incrowd who can and do edit and when they do not like what someone else does, they have ample opportunity to frustrate and make the work impossible. THAT is why it is not about anyone in particular but about how we deal with imports, each other and questions of notability for the subject matter we champion. GerardM (talk) 19:08, 30 November 2019 (UTC)
NB did anyone actually READ the article about Burke's? What version of its data are we actually using.. From a qualitative point of view, its quality is not more that that it is IN this list. Thanks, GerardM (talk) 08:25, 1 December 2019 (UTC)
@Tagishsimon: GZWDer (talk • contribs • logs) deserves all the crude sticks and wet trouts due. Hi/hers massive, unilateral, undiscussed (and possibly copyright violating) importation of hundreds of thousands of problematic items, many of which duplicate existing items, is the root cause of much woe previously and currently aired on this very message board. GZWDer, you should have solicited input for best practices and preliminary review before bringing in this mountain of crap. The Peerage is by no means authoritative, nor error free, nor complete, and it should never, ever, be construed as such. It's literally the work of one guy, impressive though it is. -Animalparty (talk) 04:47, 2 December 2019 (UTC)
Is there an implication that a source used in Wikidata is "error free"? I thought not; and that that is why we have the ability to hold two, contradictory, and cited, statements. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits10:30, 2 December 2019 (UTC)
Really, we have had and, still have tons of discussions on ceb.wikipedia, on geographic data. We prevent the use of the one tool that imports data from ORCID for "qualitative reasons" and here we have a source where scientists indcate that Burke's is largely an invention. It supports an establishment that is alive and well in the USA and the UK. So not, it is not only not "error free" it is also prejudicial. I have asked for the reason for having this data, I have indicated that the data duplicates so much of what we know, makes disambiguation truly problematic and it establishes an unnecessary bias in our data. So don't start me on error free. GerardM (talk) 18:20, 3 December 2019 (UTC)
When using a property you should read it's description. The description of "publisher" is "organization or person responsible for publishing books, periodicals, games or software". The omnious organziation "dataset" is not responsible for publishing "United Nations Office for the Coordination of Humanitarian Affairs Chad"
If you determine wikidata should be storing information on the publication and its publisher, then it - the publication - should have an item, with a statement identifying its publisher. --Tagishsimon (talk) 16:20, 26 November 2019 (UTC)
Thanks for the clarifications. :) Maybe this is not meeting the notability criteria. I am about to gain access to this dataset (to be released under CC0 hopefully), which is the only reason I created the item. WDYT, should we have an item for all released datasets in the world? The webpage https://data.humdata.org has a lot of datasets and it might or might not be worth it to have an item for each of these in WD. I personally think that if I was a researcher looking for datasets it would be really nice to query WD to get a list of them.--So9q (talk) 20:31, 26 November 2019 (UTC)
I came across few of these yesterday. I don't think it's forth creating items like unknown Brudenell-Bruce (Q75240168). Currently there are 74 of these.
There are also items like Thomas Miller (Q75707302). Supposedly we could keep them if they are linked from some other item. There are several thousands.
Actually they are here as part of family tree. Many of them are described in books so they seems notable by itself. Sometimes not having items for them will make relation impossible to express.--GZWDer (talk) 19:09, 21 November 2019 (UTC)
@GZWDer: Will you be creating item labels for the recent 300k+ item Peerage import? Search discovery is devalued to the extent that users have to pull up the full records of each of the e.g. 7 Sarah Thompsons you've just added so as to ascertain they're not the single Sarah Thompson for which e.g. a sitelink is required. --Tagishsimon (talk) 19:35, 21 November 2019 (UTC)
(edit conflict) It should be pointed out that these are imported from The Peerage (Q21401824), which while valuable and useful, and often sourced, is basically the work of one guy, who admits it is incomplete in sections and may contain errors (it certainly contains omissions of some children). It's likely that at least some of the "unknown Millers" and "unknown Smiths" etc. are already known from other sources, or will be identified in the future, by either direct documentation or inference. The Peerage is strongly biased towards British and European families, and, from casual perusal, marriages into American families are under-documented, perhaps by design. -Animalparty (talk) 19:57, 21 November 2019 (UTC)
genealogics.org is another website with some additional information, but I'm not sure how can the information be imported to Wikidata - 1. The content are one entries per page, which means we need to scrap 700000+ pages to get all entries; (however, There's an API to get all ancestors up to 8 generations, which will make import easier) 2. The site employs an automatic process to detect data mining, but I don't know how this is enforced; 3. How to detect duplicates from entries already imported from other sources.--GZWDer (talk) 20:09, 21 November 2019 (UTC)
The problem is that every family eventually has some unknown parents .. If there isn't much more to say about them, I don't see the point of creating items for them. It's clear that other website might have entries for every human. --- Jura19:42, 21 November 2019 (UTC)
The default used for CBDB and ORCID creations, where no other useful information is at hand, is along the lines of Xue Tinggui (Q18906638) "person, CBDB = 95054" or Da-Yong Wang (Q54958328) "researcher ORCID: 0000-0002-9013-1199" which have the benefit of allowing users to see from search results that these are not the e.g. shotputter they're trying to add a sitelink for. It greatly speeds up discovery when it can be seen that this item belongs to a certain set - CBDB, ORCID, Peerage. The alternative, as I noted, is that one must pull up each item one by one; and this takes a very great deal of time to do. --Tagishsimon (talk) 19:48, 21 November 2019 (UTC)
For first two, it's not really optimal, but probably a somewhat ugly, but reasonable compromise. Makes excluding them easy.
For the peerage ones, YOD should definitely be included, otherwise items for US/UK people will just become unworkable. Adding "British" in the description of people who may not be seems problematic. This still doesn't solve the problem of creating items for "unknown (?)". --- Jura20:04, 21 November 2019 (UTC)
Not every people have a DOB/DOD. In 719120 records 362103 (50.4%) have DOB information and 265589 (36.9%) have DOD information. These include non-precise ones like circa, before, between, etc.--GZWDer (talk) 20:15, 21 November 2019 (UTC)
I'm not adding descriptions to any items with preexisting descriptions, so the Osama bin Laden example is a red herring. The majority of these are unknown and insignificant relations of a royal family. The lack of descriptions have already created significant difficulties with searching and reconcilation. Gamaliel (talk) 20:33, 21 November 2019 (UTC)
You are adding "British peer or relation" to items about people how may not be British. Please hold this for now. --- Jura20:54, 21 November 2019 (UTC)
Sure, temporarily. Can we also hold off on the creation of new blank Peerage items? In addition to the search and reconciliation issues there are also a large number of duplicates. Gamaliel (talk) 20:57, 21 November 2019 (UTC)
As there's a name index in The Peerage, there's few internal duplicates. Most of the duplicates exists because of different transcription of foreign names.--GZWDer (talk) 21:22, 21 November 2019 (UTC)
Sorry, I didn't mean duplicates in The Peerage itself, I mean that you are creating duplicate Wikidata items. A lot of this is from labels that are not in the proper format for Wikidata - e.g. Rev. John Smith vs. John Smith, etc. Gamaliel (talk) 21:27, 21 November 2019 (UTC)
I'm indifferent as to which format is proper, if any, and the more aliases the better as far as I am concerned. The real issue is the duplicate Wikidata items being created. Gamaliel (talk) 21:53, 21 November 2019 (UTC)
@GZWDer: This item doesn't allow you to express anything that you can't currently express with <unknown value>. If you know nothing about the father of John Smith besides him being the mother and need an item for the father because you want to store his occupation, you might create in the worst case an item named "father of John Smith" which would be more informative then if the item is named "unknown" which might be easily confused with other people for whom we don't know the name as well. ChristianKl ❪✉❫ 20:31, 21 November 2019 (UTC)
@GZWDer: Was there a request for Permission for User:GZWDer (flood) to mass import entries from The Peerage? I'm not alleging any wrongdoing, but mass imports from any large database should be scrutinized for potential errors and hiccups well before they begin. -Animalparty (talk) 21:01, 21 November 2019 (UTC)
I have checked all people with a child with Peerage ID. There're various errors in both Wikidata and The Peerage.--GZWDer (talk) 21:07, 21 November 2019 (UTC)
There are undoubtedly errors in both sources, as is to predicted for any genealogy database (I've seen errors in larger sources like Geni.com that list sisters as spouses, e.g.). Which is why preliminary scrutiny is important. What do you mean by "checked all people with a child ID"? There have been many duplicates created already, including people already with a Peerage ID. Do you have a plan to identify and merge all duplicates? If you plan to do more bot-automated tasks, such as mass merges of duplicates or linking items through marriage or lineal descent, it should be absolutely transparent and reviewed beforehand to allow troubleshooting or at least a forewarning for people understandably concerned about where the change is coming from. You're creating a lot of dust along with your construction: hopefully when the dust clears all be will worked out with minimal extra effort, but an "in construction" notice certainly couldn't hurt. -Animalparty (talk) 22:07, 21 November 2019 (UTC)
In my opinion duplicate is less a problem than incorrect match. Duplicates will be more easy to find once more data are added.--GZWDer (talk) 22:48, 21 November 2019 (UTC)
One issue is whether it's worth merging duplicates by hand, or whether one should wait: since the scope and aims of your Peerage bot import aren't clear, would it hinder some undisclosed master plan in the works if duplicates are merged manually? And again I think you should clearly state exactly what your bot will be doing, and how it will go about doing it. Are you importing the entirety of The Peerage? Will your bot add descriptions and birth/death years to the items has created? Will it add all family linkages? How will it handle entries that already have items? Will duplicates be merged automatically or merely flagged for human review? -Animalparty (talk) 23:43, 21 November 2019 (UTC)
They are husband of someone (it may take another several days to import all spouse relations). Actually the father-in-law of both people have a Wikipedia article.--GZWDer (talk) 21:10, 7 December 2019 (UTC)
@GZWDer:this was started 3 weeks ago it hasnt taken some days... and if you know something why add those empty items at the first place... and why continue adding new... why adding no location or date estimates... now everyone else has to check every item to understand what it is... this is more like something for a genealogy sites were people massimport things they hope is true... my understanding is that sites like Wikitree has stopped those massimports because all the mess it creates...
The Peerage should only be a provisional source. It is more reliable than WikiTree/Geni/WeRelate which are user-generated with little review, but if there's some more reliable sources (like Burks'), it should be used instead eventually. Otherwise The Peerage may still be used as a (not very good) secondary source.--GZWDer (talk) 21:59, 7 December 2019 (UTC)
@GZWDer: now Wikitree discuss this massimport see linkBot import of The Peerage data in Wikidata - Good or Bad News? every week WikiTree checks its > 20 000 000 profiles with more sources like Wikidata see latest report "Data Doctors Report (December 1st 2019)" Wikidata check are 541 - 569. You can also see the statistics link
the number of "has mother" relationships in Wikidata as Aug 1st, 2019 was about 62,000. It's now over 480,000.
if we are lucky WikiTree correct errors and regarding to the discussion so is Darryl at thepeerage fast updating his tree the problem I see now is that Wikidata will not be updated as we are out of the loop?!?!?. Question @Lesko987a: is there a WikiTree feed that e.g. GZWDer can use to see what is corrected in WikiTree compared to what we have in Wikidata? My feeling is that when we Wikidata and WikiTree has a mismatch WikiTree people just mark Wikidata as wrong and nothing is changed in Wikidata. I guess this import adds Wikidata objects that never will have a Wikipedia article and I guess they will get less cared about than profiles in Wikitree and Wikidata profiles with Wikipedia article. Will Wikidata be the new loser sitting with data that is never updated... is there a plan for a dataroundtrip? - Salgo60 (talk) 00:11, 8 December 2019 (UTC)
We have no feed, that could be used for this. I do run compare of the databases each week and create the Error report on WikiTree with the goal to improve WikiTree data. Something similar could be done for WikiData, but I don't know who would look into it. Now when thepeerage import was done, I could do something similar for Wikitree. I however wouldn't create new items, since there would be 20M of them, but I would add different data from wikitree to wikidata and only references to matching data. I will decide about this in the future. Now I have more than enough work on all new data from thepeerage. the import created 1000s of duplicated items. – The preceding unsigned comment was added byLesko987a (talk • contribs) at 8 december 2019 kl. 17.14 (UTC).
Lesko987a Thanks for the feedback. I think today there is no good way of adding suggestions to Wikidata more than directly update Wikidata. We have for matching external sources Magnus Manske tool mix-n-match (catalog The Peerage) were he automatch and then you can manually match/confirm matches to WD objects. I feel Wikidata should have a 'dataroundtrip tool were we can manually confirm a change to a fact that is an update done in e.g. WikiTree/The Peerage... - Salgo60 (talk) 10:59, 9 December 2019 (UTC)
Example how WikiTree works to improve quality WikiTree Coventry-182 is marked unsourced BUT its now same as Diana Bruen Coventry (Q75322552). Lesko987a has created this infrastructure that I feel is the future of Linked data when we have data of less good quality. On every WikiTree profile you have a menu option suggestions see example Diana Bruen (Coventry) Mason (1910 - 1990) and we get a list of 8 generations errors starting with selected person and by default 1245 profiles has been checked and have 307 potential errors.... If you check the list maybe > 50 are suggestions based on Wikidata as Wikidata now has start do imports of less good sources and also creates new objects just based on this "source"
Good or bad? the feeling I get when seeing the work done so far its touch and go and hope that someone else will do the dirty cleaning work... I feel Wikidata miss a concept of Quality for sources (see thoughts) and this is very important when importing data!!!! Wikidata miss a data roundtrip concept How should Wikidata get changes done in Peerage/WikiTree/??? "back" to Wikidata We can argue for weeks if a property should be created or not and we need to do the same with imports like this.. - Salgo60 (talk) 10:41, 8 December 2019 (UTC)
Various items (ca. 150,000) from the recent bot created items now have a description "British peer or relation".
While some prefer these as they are literally not incorrect, the description probably applies to all of us: it does NOT mean, that you are British, a British peer or a direct relation of a British peer.
From the discussion on Administrators'_noticeboard it appears there is no consensus for these additions. Personally, I think they are biased and accordingly don't meet Help:Description.
This is a general question impacting all users. Unrelated to the discussion of the block of the person who didn't stop adding them. --- Jura17:38, 24 November 2019 (UTC)
Make descriptions less prominent, instance/subclass statements more prominent in general. For example, hide descriptions/aliases (visible with arrow-thingy). --SCIdude (talk) 18:00, 25 November 2019 (UTC)
Since the problem is mainly how to effectively label and disambiguate the thousands of entries imported by GZWDer from The Peerage, the boilerplate stamp "British peer or relation" doesn't help differentiate them (we will end up with of thousands of identical descriptions, many with similar or identical labels). "European peer or relation" is even vaguer and not meaningfully helpful. In the absence of any other knowledge, something more unique like year of birth and/or death would be preferable to the boilerplate. If someone was particularly bot savvy, and I'm just spitballing here, perhaps some description could be gleaned from the title in The Peerage, e.g. if a person is listed as "John Smith, Baron Smith", a meaningful description would be "British baron, died 1789". Repeat for all dukes, duchesses, marquesses, baronets, etc. -Animalparty (talk) 20:45, 25 November 2019 (UTC)
I could do the date and title in OpenRefine easily enough, there's just not a way to glean national origin from the existing Wikidata items. That still leaves many relations without titles, as well. Gamaliel (talk) 21:30, 25 November 2019 (UTC)
Also it seems problematic to do that for items about living people in countries like Austria .. --- Jura06:19, 26 November 2019 (UTC)
Restoring this section for an update: cleanup is mostly done. An item for Arnold S. had the same description. I removed the "British peer or relation" descriptions from "en" and replaced it with YOB/YOD. A question that came up is what to do with living people: I noticed that the same user who we spent moping up behind them, now started adding year of birth to these. What do people think of that? I avoided that year of birth isn't necessarily helpful as only description for living people. --- Jura06:15, 6 December 2019 (UTC)
I too am a bit uncomfortable about the information on living people. Full disclosure: I am myself one of the living people who has now acquired a Wikidata entry, with data too on all my nearest family and the minutiae of how we are all related to each other, even my teenage relatives. Not something I think is particularly comfortable. To be in line with our BLP policy, I think these entries for living people should probably be removed unless people are for some other reason notable; and even when living people are independently notable, data should be limited to what is widely publicly available, rather than what may be in obscure genealogical databases. Though it may be necessary to more fully integrate the database first, before such content can be pruned out most accurately. Jheald (talk) 19:48, 7 December 2019 (UTC)
Personally, I avoid adding year of birth in descriptions for living people. There are does seem to be a considerable number of items about minors and living people in the dataset (20%?). --- Jura13:48, 9 December 2019 (UTC)
In English (like the French equivalent autographe) the word autograph can have two meanings (copying from wiktionary, but the same is confirmed by any English and French dictionary):
(...) the signature of a famous or admired person.
In other languages, for instance Dutch, there's not a single word for both meanings:
the first meaning can only be translated as "handtekening", never as "autograaf"
the second meaning can only be translated as "autograaf", never as "handtekening"
That language has no word covering both meanings.
At English Wikipedia, I started a new article on the "manuscript" meaning of Autograph, i.e. en:Autograph (manuscript). The Q number for this article should connect to:
I support the initiative of Francis Schonken (talk • contribs • logs) of splitting the two concepts in WD and to explain the modification in Commons. After that if Commons prefer to keep the current situation, they are free, but there will be a problem to connect the item and the category. Both projects (commons and WD) are free to define their own organization and none can force the other to change. But WD is not suppose to adapt its ontology according one specific project. Snipre (talk) 14:04, 30 November 2019 (UTC)
commons:category:Autographs was never intended to contain mere signatures. There is a commons:category:Signatures for that. The former is probably poorly named, and has been repeatedly misunderstood as a result, but the intent has always been that. I added a further sentence just now to the description at the top of the category, trying to further emphasize this. Personally, I think the category should be renamed, and will propose that. Meanwhile, there is no ambiguity in the intent on Commons, and we should go with the intent, even if the implementation there is flawed. - Jmabel (talk) 18:31, 30 November 2019 (UTC)
Re. "I added a further sentence just now to the description at the top of the category, trying to further emphasize this." – I undid that very contentious edit.
Re."... repeatedly misunderstood ..." – don't accuse others of misunderstanding if you don't understand yourself (apparently).
Probably we should better continue the commons category discussions at commons (they don't belong here, as someone has already remarked above). --Francis Schonken (talk) 21:05, 30 November 2019 (UTC)
I tried to sort the articles of the Wikipedias of all languages I could understand enough in the correct Wikidata items above. Whatever languages you understand or read, please check whether these wikidata listings are correct.
Also exist (to illustrate that articles on autograph signatures are different from articles on signatures):
 Done. Multichill (talk) 22:24, 3 November 2019 (UTC)
Done. Multichill (talk) 22:24, 3 November 2019 (UTC) Support your approach. This use of instance of (P31) when it more logically should be subclass of (P279) is a very general problem within wikidata's class hierarchy, and we've been rationalizing it a bit with arguments about metaclasses, but I think just converting more of those abstract relations to subclass relations would work in most cases (and I agree it makes sense in this one). ArthurPSmith (talk) 17:17, 21 October 2019 (UTC)
Support your approach. This use of instance of (P31) when it more logically should be subclass of (P279) is a very general problem within wikidata's class hierarchy, and we've been rationalizing it a bit with arguments about metaclasses, but I think just converting more of those abstract relations to subclass relations would work in most cases (and I agree it makes sense in this one). ArthurPSmith (talk) 17:17, 21 October 2019 (UTC) Comment$ I think the general question is which ones are instances of units and which ones are classes of units. Anything with a SI conversion should be an instance. --- Jura 13:55, 23 October 2019 (UTC)
Comment$ I think the general question is which ones are instances of units and which ones are classes of units. Anything with a SI conversion should be an instance. --- Jura 13:55, 23 October 2019 (UTC) Oppose There's some leak in this scheme, and I can imagine where. Compare density (Q29539) and intensive quantity (Q3387041). In your scheme they are both subclasses of physical quantity (Q107715) which is illogical. From my point of view physical quantity (Q107715) should be M2 (metaclass), intensive quantity (Q3387041) and similar would be its subclasses (and thus also M2), and items like density (Q29539) (which has definite units of measure) are P31 of any previous (and thus M1). I don't care about M0 (which you call "individual quantities" but I'd rather call them "individual measurements") now as they seem to be rare in WD, but I suspect that there should be another relation (not P31) between them and M1-quantities. --Infovarius (talk) 22:58, 27 October 2019 (UTC)
Oppose There's some leak in this scheme, and I can imagine where. Compare density (Q29539) and intensive quantity (Q3387041). In your scheme they are both subclasses of physical quantity (Q107715) which is illogical. From my point of view physical quantity (Q107715) should be M2 (metaclass), intensive quantity (Q3387041) and similar would be its subclasses (and thus also M2), and items like density (Q29539) (which has definite units of measure) are P31 of any previous (and thus M1). I don't care about M0 (which you call "individual quantities" but I'd rather call them "individual measurements") now as they seem to be rare in WD, but I suspect that there should be another relation (not P31) between them and M1-quantities. --Infovarius (talk) 22:58, 27 October 2019 (UTC)

 Sigismund Casimir of Poland (Q2405577) - "British peer or relation"
Sigismund Casimir of Poland (Q2405577) - "British peer or relation" Bertrand VI de La Tour d'Auvergne (Q1389348) - "British peer or relation"
Bertrand VI de La Tour d'Auvergne (Q1389348) - "British peer or relation" Mathilda of Bavaria (Q3298973) - "British peer or relation"
Mathilda of Bavaria (Q3298973) - "British peer or relation" Vladimir Sheremetev (Q16977139) - "British peer or relation"
Vladimir Sheremetev (Q16977139) - "British peer or relation"!["British peer or relation" [1]](//upload.wikimedia.org/wikipedia/commons/thumb/a/ad/Arnold_Schwarzenegger.JPG/98px-Arnold_Schwarzenegger.JPG) "British peer or relation" [1]
"British peer or relation" [1]



!["British peer or relation" [1]](/wiki/File:Arnold_Schwarzenegger.JPG)
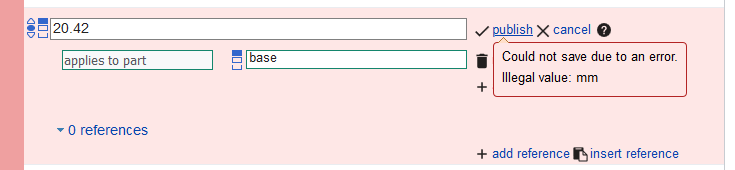{kind=link}
_cemetery_plot_in_Cypress_Hills_Cemetery_on_April_23,_1999.jpg){kind=link}
.png){kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}